Sign up for smart news, insights, and analysis on the biggest financial stories of the day.
A new mega talent is making a big splash in publishing, and everyone is desperate to know: who is this ChatGPT? And who are its biggest influences?
At recent meetings hosted by publishing trade group the News Media Alliance, according to a report by The Wall Street Journal, publishers wondered out loud if Silicon Valley’s so-called large language models are largely modeled after their intellectual property… and if publishers are therefore entitled to any AI-generated profits.
Do Large Language Models Dream of Electric Sheep?
Publishers spent the past two decades desperately arguing that Big Tech made countless billions off of their content (i.e., nobody would use Google if The New York Times or ESPN didn’t appear in search results). But now yet another tech paradigm shift is upon us, and publishers are again leaning on their back foot to wade into the constantly-evolving frontlines of AI.
AI’s output of zippy summaries of news events inherently terrifies (and entices) the desperate-for-clicks publishing class. But the human content purveyors and AI developers may have a much trickier legal quandary on the input side of the equation. After all, The “P” in “GPT” stands for “pre-trained.” As in, OpenAI and its competitors trained its large-language models with billions of bits of data and published content from across the web. Thus, publishers see their work being reused and commodified in nearly every ChatGPT and Google Bard response — not just the ones erasing search traffic.
But whether or not Silicon Valley had any right to pump all that content into their own personal chatbot/possible doomsday machine is another question entirely:
- OpenAI has argued that “fair use” copyright laws allow for fairly liberal use of scraped online material, though has conceded it has struck deals for certain specific, often highly technical content. Google and Microsoft, meanwhile, have implemented some source-citing and linking in their bot responses, but publishers say the practice remains far too limited.
- Congress may soon pass legislation allowing publishers to collectively negotiate with Big Tech without stepping on antitrust tripwires, and the US Copyright Office last week began a study on AI’s reading material. In other words, we’re still in the legal wilderness.
Learn to Code: Ironically, techies have their own AI copycat problem. GPT4, OpenAI’s recent ultra-powerful ChatGPT update, has shown itself to be fully capable of writing code to create apps and software — likely riffing off existing code in the process. The big hoopla, of course, will come on the possibly not-too-distant day when AI is capable of creating another AI, which can create another AI, which can create another AI, which can… well, that’s a story plenty of human writers have written before.
Recent News




-
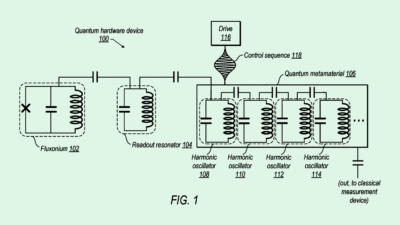
DeepMind Patent Gives AI Robots ‘Inner Speech’

Photo via U.S. Patent and Trademark Office
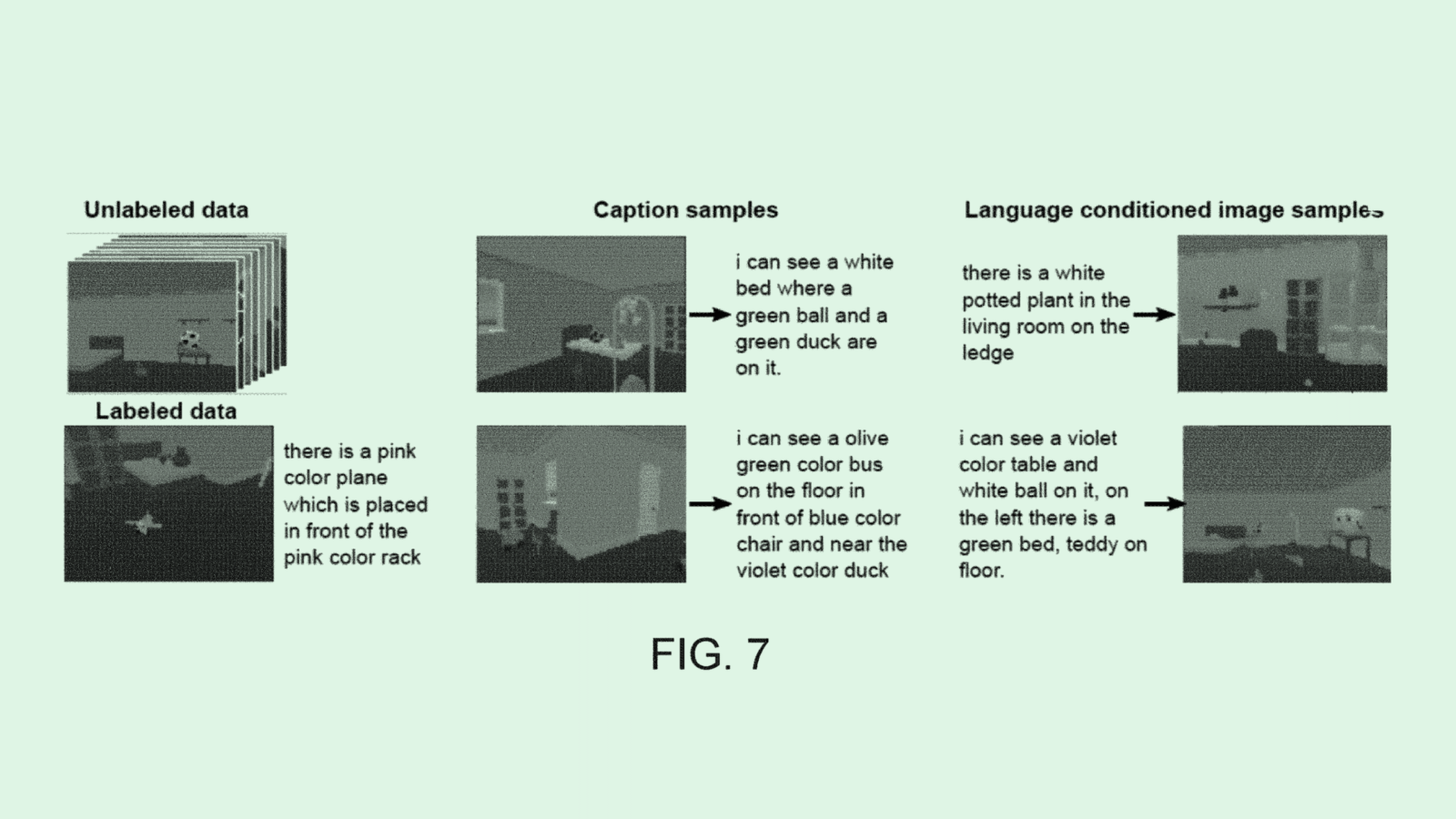
-

Photo via U.S. Patent and Trademark Office


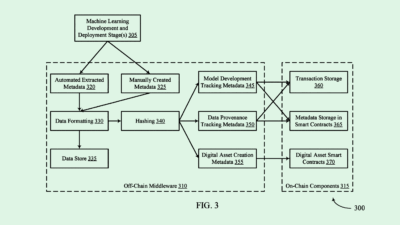

-
Photo via U.S. Patent and Trademark Office