Happy Thursday and welcome to CIO Upside.
Today: Our lead reporter Nat Rubio-Licht spent the week in Las Vegas at ServiceNow’s Knowledge 2025 conference. The big takeaway: Keeping your AI isolated isn’t doing your enterprise any good. Plus, why AI education isn’t matching employer demand; and DeepMind’s patent seeks to make small models more powerful.
Let’s jump in.
Isolating AI Agents May Be ‘Strangling’ Your Enterprise

Your employees talk to each other every day. According to ServiceNow, your AI should too.
As AI agents dominate the enterprise conversation, companies are still struggling to achieve real value with them. That lack of return and impact may be the result of silos that are “strangling” enterprises, Bill McDermott, CEO of ServiceNow, said in the company’s Knowledge 2025 keynote speech on Tuesday.
“The cost of this legacy inefficiency is killing us,” McDermott said.
An AI agent that is siloed is deployed for single tasks within lone systems, operating isolated from the rest of an organization’s departments or data sources. Think of it as an employee who’s cut off from coworkers: Isolation deprives an AI agent of context that it could use to learn, operate and better serve its purpose, Kellie Romack, ServiceNow’s chief digital information officer, told CIO Upside.
And it’s not hard for an organization to fall into the trap of creating silos in the first place, Romack said. Starting with small, individual use cases for AI agents naturally lends itself to compartmentalization. The problem is when it stays that way, she said, and a company’s AI strategy is grown piecemeal around it.
“A lot of folks just said, ‘Great, we’re going to add AI to our current process,’ and I think that’s where a lot of the silos occur,” said Romack. Allowing agents to operate across organizational departments could curb redundancy in having to build and deploy the same systems over and over again, Romack said.
“Make these agents work as a team; nobody lives in a silo,” said Nvidia CEO Jensen Huang, who announced a partnership Tuesday between Nvidia and ServiceNow to build a large language model for AI agents. “Just as we want all our employees to work as a team.”
Several of ServiceNow’s announcements at Knowledge focused on breaking down silos: McDermott debuted the AI Agent Fabric, which allows for agent-to-agent communication and multi-modal understanding. Additionally, the company introduced its AI Control Tower, which, as the name implies, enables enterprises to keep watch and track performance of fleets of agents.
While AI has improved tremendously in the past few years, it still poses risks. Before letting agents run the show, there are four things to consider: Validation, governance and compliance, visibility and isolation, Ben de Bont, chief information science officer at ServiceNow, told CIO Upside:
- The first step to integrating any AI agent is making sure that your models are up to snuff, he said, validating that they meet security benchmarks and adhere to legal compliance standards like the EU AI act.
- After that, you can’t just let agents run free. Monitoring and tracking these systems is vital, de Bont said. “You can’t secure what you don’t know exists.”
- Even though the ServiceNow ethos seeks to bring AI agents together, it’s important to know when one needs to be alone, said de Bont. “You still want to look at where you need to isolate it based upon the use cases that you want to put in place.”
Once the risks are managed, the payoff from AI is worth it, experts say. “Agentic is not about automating one part – it’s really end to end… you’re changing how businesses will operate,” Amit Zavery, president, chief product officer and COO of ServiceNow told CIO Upside.
“If you build AI agents for the siloed system without connecting them, you’re not changing anything… you’re not getting anything out of it,” Zavery added. “What we’re able to do now with the orchestration capabilities we’re delivering, the work we’re doing with Control Tower, is to really solve that problem.”
Enterprises Calculate ‘Build or Buy’ Differential in Acquiring AI Talent

With the AI market moving at lightning speed, can education for workers developing and operating the tech keep up?
A recent study from online credentialing company Coursera suggests it hasn’t so far.
About 92% of enterprises surveyed said they’d be more likely to hire a candidate with a generative AI credential than one without, and three quarters said they’d hire a less experienced candidate with AI education over a more experienced applicant without. Despite the demand, just 17% of students surveyed have earned AI credentials.
Meanwhile, 93% of students said they believed universities should offer AI training, and 89% reported that they’d be more likely to enroll in a degree program that included generative AI in the curriculum.
The tech’s fast-paced development is making it difficult for training and education to meet demand from employers, said Trena Minudri, chief learning officer at Coursera. “If you’re taking a more traditional approach to learning and development and education, you’re definitely having trouble keeping up.”
This skills gap is forcing enterprises into a balancing act, said Minudri. While hiring “job-ready” candidates with AI experience can reduce on-the-job training expenses, the cost of hiring those qualified employees can add up quickly, she said:
- “When you look at the cost of hiring all of your employees versus training who you have, you have to do that in a very strategic way,” said Minudri.
- And deciding which positions to hire and which to train “depends on the lift,” she said. For example, employees who already have strong skills but need to figure out how to weave AI into their duties are good candidates for reskilling compared with those who are “at 20% of where they need to be,” Minudri explained.
“The whole buy-versus-build model is a very complicated equation,” she said. “You can put data in and figure out whether you should buy or build in terms of skills, but most companies have to do both.”
Additionally, upskilling has to be about more than just checking boxes and completing a course if enterprises want to actually see a difference, said Minudri. Tracking metrics such as time saved and how workers are using that time for higher-value activities could help enterprises discern whether or not credentialing is worthwhile.
“I think we still find a lot of employers are focused on how many people completed a program, and maybe even looking at pre- and post- data, and they haven’t quite focused entirely on the return on the investment or the business impact,” she said.
DeepMind Patent Shrinks Model Size Without Compromise
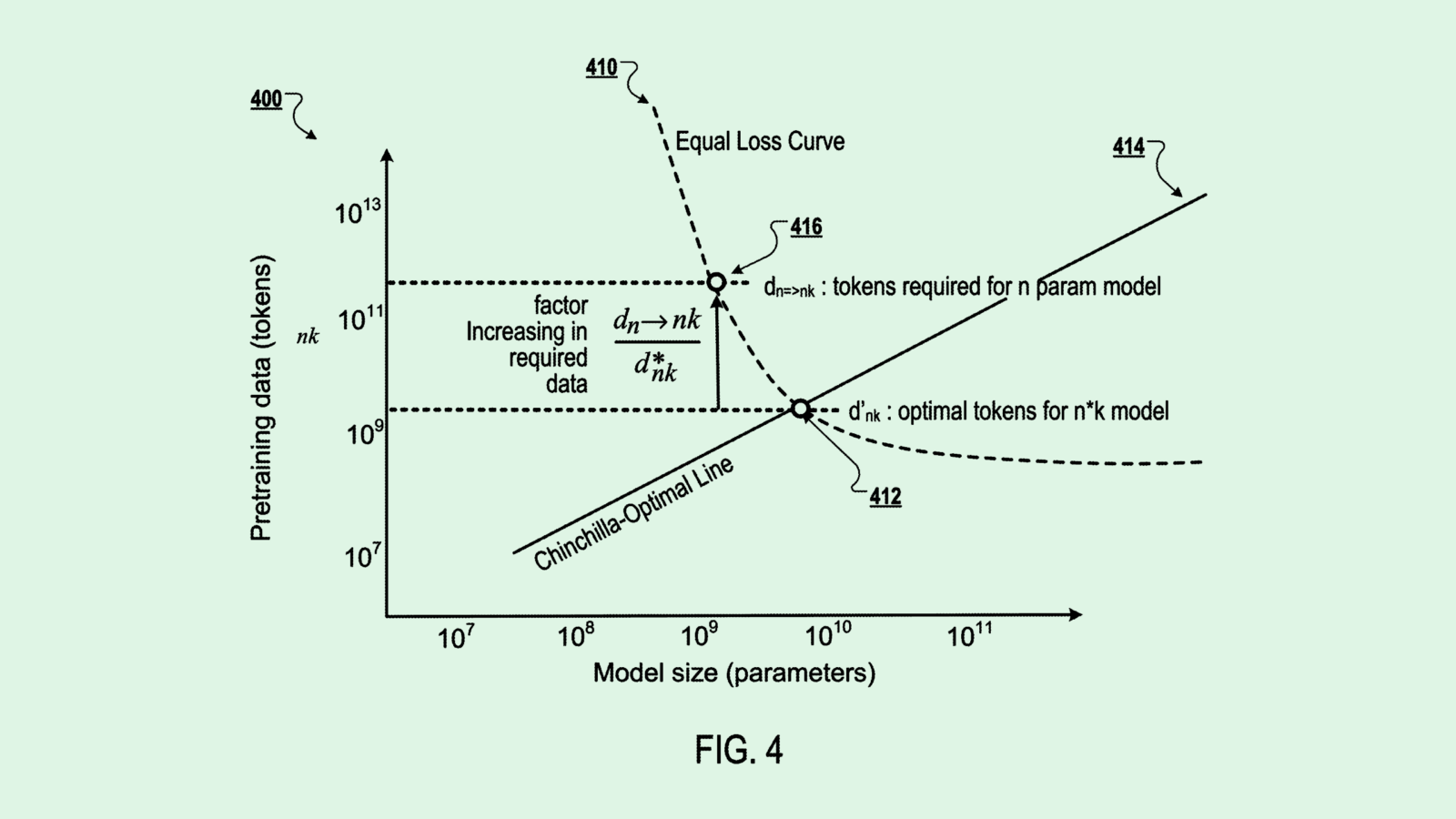
AI training data isn’t “one size fits all.” DeepMind wants to figure out exactly what’s right for each model.
Google’s AI subsidiary filed a patent application for “determining training data sizes for training smaller neural networks using shrinking estimates.” To put it simply, the tech aims to figure out how much training data a smaller model needs in order to perform on par with a larger one.
DeepMind’s system does this with what the filing calls “model shrinking mapping,” which is basically a ratio equation to figure out how much data a small model would need by comparing it with a large model and its training data. That equation allows developers to figure out exactly how much data they need, avoiding overtraining and wasting resources.
“The second model will achieve substantially the same performance as the first machine learning model despite having lower computational cost, less latency, and a small environmental impact at inference time,” DeepMind said in the filing.
Though tech giants – Google included – have been fixated on making their large language models more powerful, small and energy-efficient models have captured increasing interest in recent months:
- Last week, nonprofit AI research institute Ai2 released a 1 billion-parameter model that it says can outperform similarly sized models from Google, Meta and Alibaba in certain areas.
- And Microsoft released Phi-4-Reasoning-Plus in early May, a 14 billion-parameter model built for logic-based tasks such as math and science. For reference, large language models tend to have parameter sizes in the trillions.
Small and large models each have their pros and cons. While small models are generally more energy-efficient as well as cheaper, they suffer in terms of capability and accuracy. Large models, meanwhile, are the opposite. DeepMind’s patent proposes a system for finding a middle ground, something of growing importance as enterprises seek efficient and cost-effective AI.