Microsoft’s Data Detective
Microsoft wants to pick out the bad apples in AI training data.

Sign up for smart news, insights, and analysis on the biggest financial stories of the day.
An AI model is only as good as the data it’s trained on. Microsoft wants to make its data as neat as a pin.
The company is seeking to patent a system for improving machine learning models by “detecting and removing inaccurate training data.” Microsoft’s system essentially works by picking out the outliers. Ironically, it relies on a machine learning model trained to evaluate training data and come up with a “prediction confidence level” determining if the sample is both erroneous and varies too much from the rest of the dataset.
Microsoft’s tech specifically intends to improve machine learning-based classification, which is widely used across industries, including cybersecurity, logistics, autonomous driving and consumer tech, the company noted. Its system aims to weed out data that’s been inaccurately categorized or labeled due to human error, machine bugs or conflicts.
“As a result, ML model accuracy may be improved by training on a more accurate revised training set,” Microsoft noted.
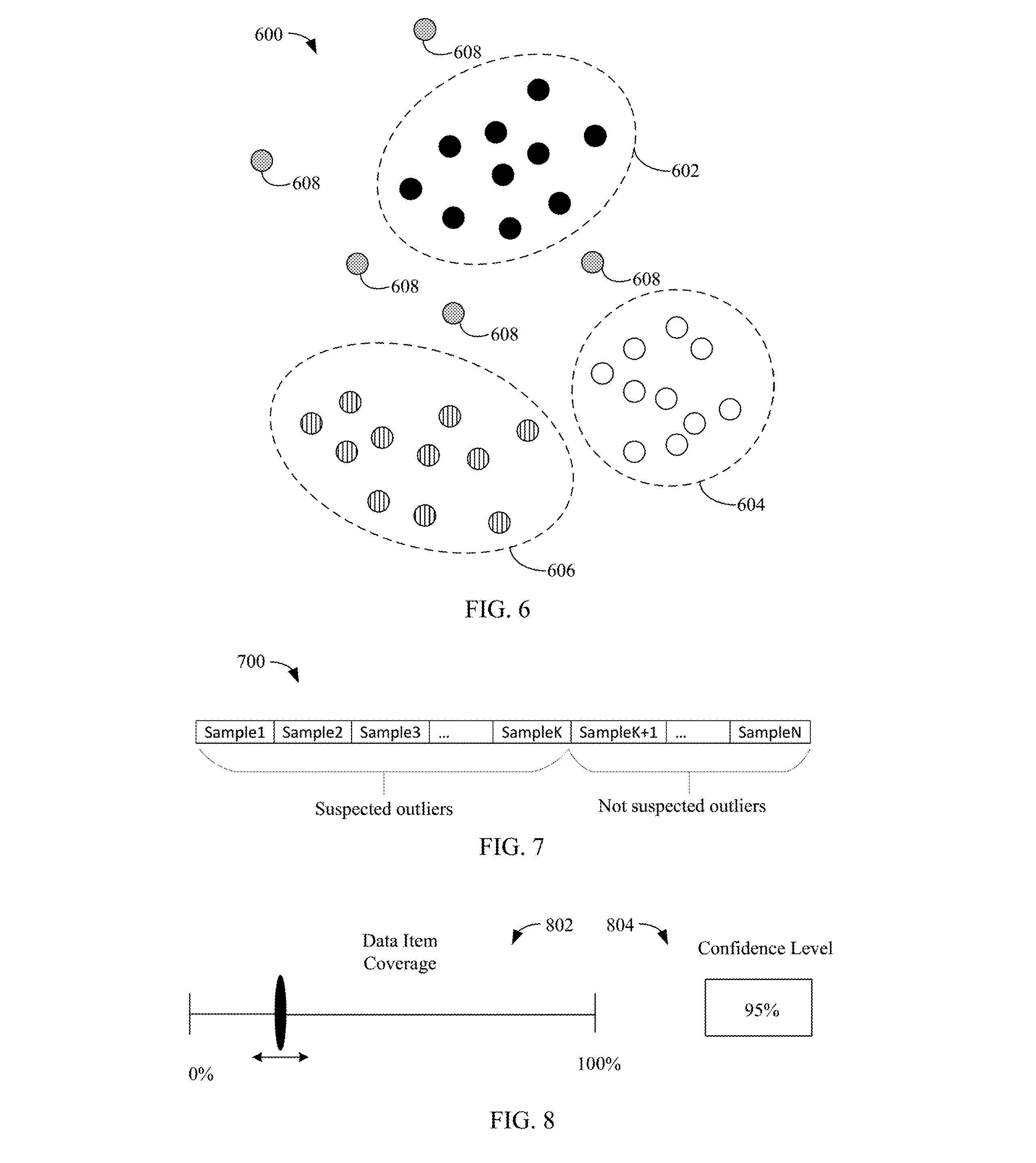
Don’t want to dig up datasets yourself? Microsoft is working on that, too.
The company filed a patent application for a “machine-learning training service” using synthetic data. Microsoft’s filing details what it calls “synthetic data as a service,” which provides a machine learning training system that “allows customers to configure, generate, access, manage, and process synthetic data training datasets for machine learning.”
Microsoft’s system creates training datasets by taking synthetic data assets, such as 3D models and scenes, and altering the “intrinsic” and “extrinsic” parameters, or things like location, orientation and focal length when looking at the 3D scene. The system also takes the manual labor such as labeling, tagging, and updating out of developing datasets.
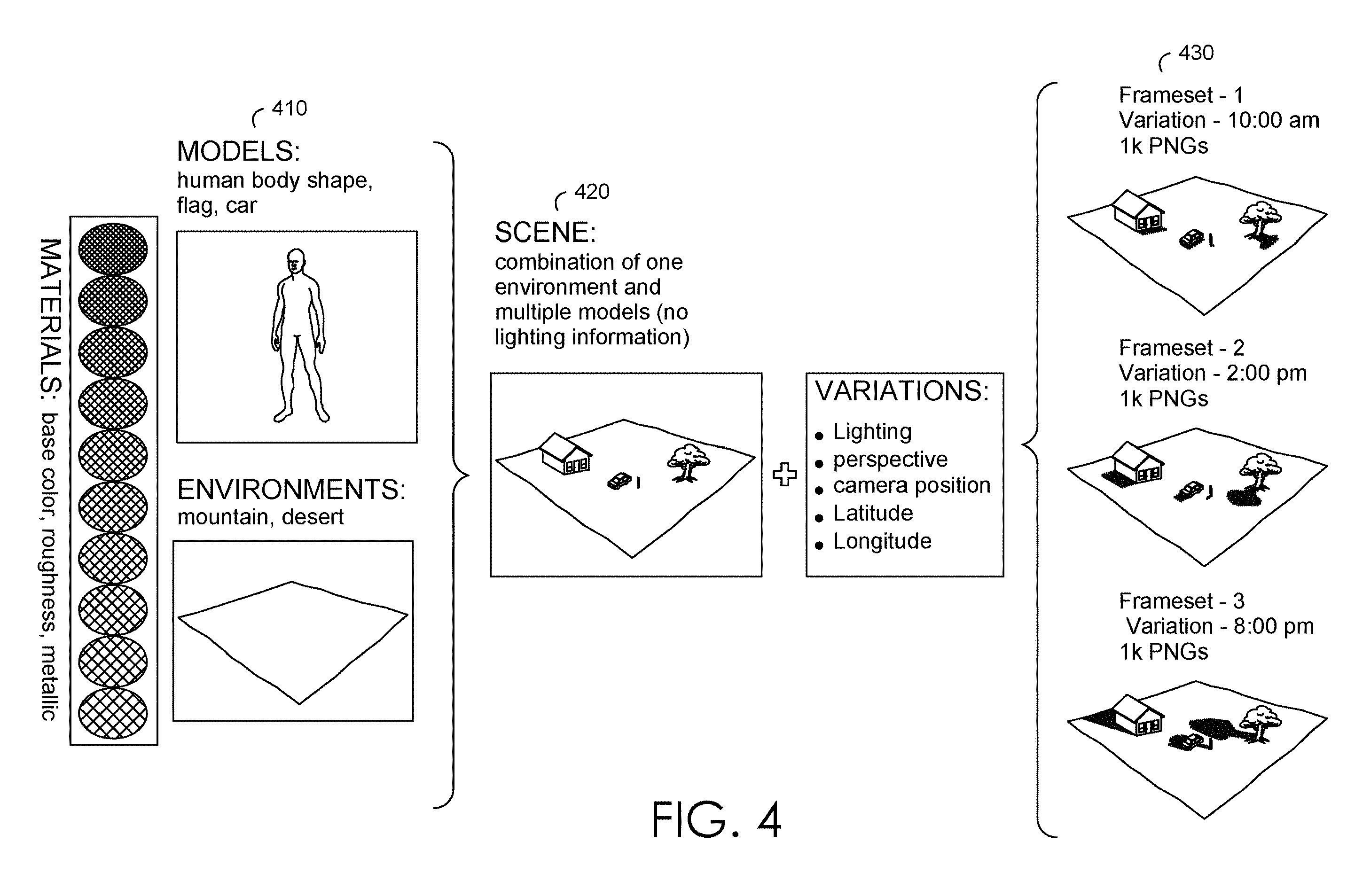
Ensuring the quality of a dataset can become “quite a bottleneck” in developing AI, said Kevin Gordon, co-founder of AI consulting and development firm Velora Labs. With the wellspring of data that Microsoft can access, finding a way to efficiently organize it could speed up the entire process. That said, Microsoft’s tech to train and detect inaccurate data would more likely be put to use internally, rather than sold as a service, Gordon said.
The company’s “synthetic data as a service,” on the other hand, could help enable tons of small startups and individual developers to work on their own AI models much more easily, Gordon said. This is doubly true for those that are just dabbling in AI and don’t have “hordes of people helping with the data side.”
“It might not be the tool that’s really aimed towards big companies,” said Gordon.
But similar to NVIDIA’s work with synthetic data, securing this patent may prove difficult. There are plenty of companies, big and small, innovating and competing in the synthetic data space.
“There are a lot of people in big organizations with the legal power behind it that are also working on (synthetic data),” said Gordon. “I can see these being quite tough unless (Microsoft) can attach it to something a little more concrete that they can narrow the scope on.”
Have any comments, tips or suggestions? Drop us a line! Email at admin@patentdrop.xyz or shoot us a DM on Twitter @patentdrop. If you want to get Patent Drop in your inbox, click here to subscribe.
Recent News




-
Apple Shows Off Gemini-Powered AI At WWDC

Photo via Apple





-

Photo via Marijan Murat/dpa/picture-alliance/Newscom -


