Google’s Content Moderation Tech May Need Human-AI Teamwork
Google wants humans and AI to work together to fight spam.

Sign up to uncover the latest in emerging technology.
Google wants to make sure the content it serves to users is of the highest quality.
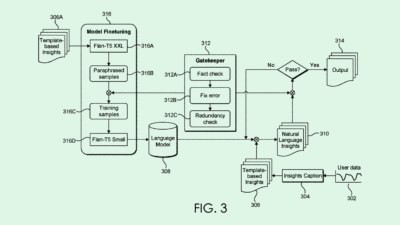
The company filed a patent application for a system to “protect against exposure” to content that violates a content policy. As the name implies, this system hides content items based on whether or not it violates a platform’s policies, using a machine learning algorithm to make that determination.
The system relies on a machine learning model that’s trained to identify when content isn’t in line with a platform’s content policy. Google says the system may tackle a broad array of content, including text, images, video and sound. If the content surpasses a certain threshold, it’s withheld from going viral.
Google’s method uses what it calls a “proportional response system” to make determinations about content items in batches, essentially figuring out what percentage the content within the batch surpasses the threshold to decide whether or not to classify the entire batch as in violation of policies.
However, Google doesn’t stop at an AI-based flagging system. If the machine learning model is stumped by a particular batch of content, the system requests a human reviewer to check it out and make the determination. This could lighten the load of manual content moderators by only requesting reviews when the AI can’t figure it out.
Google said its system could prevent content with adult themes, such as videos with alcohol, firearms or tobacco, from being served to “impressionable audiences,” without needing a human reviewer to categorize every single content item that gets posted to a platform. Its system also could mitigate inappropriate content from being incorrectly flagged as safe for all audiences.

While AI content moderation typically has been good at classifying topics when it comes to text, images, video and audio have largely been harder for an AI model to understand, allowing things to slip through the cracks, said Grant Fergusson, Equal Justice Works Fellow at the Electronic Privacy Information Center. Google’s patent attempts to get around this by batching out these content items and taking action proportionally, essentially making it more cautious.
However, for a machine learning model to take into account a content policy, the policy itself has to be incredibly straightforward, said Fergusson. “So if there are any confusing parts about the content policy, any sort of issues with the content policy that might not make sense from a strict rule standpoint … that’s not something that an automated system can do very easily.”
Google’s patent tries to get around this by adding a human reviewer to certain cases, but without the help of human intervention, the intentions of a content policy may get lost in translation, he said.
One potential advantage, however, is that Google’s system could potentially allow it to mold its policies to the regulatory needs of specific states or countries, as regulations regarding social media moderation and content continue to change, said Fergusson.
“This is one opportunity to try and automate the process to make it easier for companies to comply with … this patchwork (of policies) that sometimes don’t make sense,” he said. Whether or not this method will actually work, he noted, “is still up for debate.”
Google has a few things to gain from securing this patent. For one, this tech could be applied to its own services, whether that means monitoring kid’s content on YouTube, taking down misinformation in large batches of search results or even targeting ads in a more curated way, said Fergusson.
Plus, patenting this adds to the myriad of spam-fighting and content moderating inventions that Google has sought to make proprietary. The more it adds to its collection, the more other platforms or sites would become reliant on its services, Fergusson noted. “That’s interesting on a larger, contextual level as we’ve seen people start to move a bit away from Google searches, going towards searching on other digital platforms,” he said.
Recent News
-
Google Patent Highlights AI and Quantum’s Symbiotic Relationship

Photo via U.S. Patent and Trademark Office

-

Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office



-
Microsoft’s Cybersecurity Strength Could Boost AI Bet
Photo via U.S. Patent and Trademark Office

-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office


-
Google May Be Giving Glasses Another Go. Will It Succeed?
Photo via U.S. Patent and Trademark Office
-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office