Google’s Smart Speakers May Add to Global Data Melting Pot
Google wants its smart speakers to learn from their mistakes. The company’s latest patent reveals plans for its devices to take feedback.

Sign up to uncover the latest in emerging technology.
Google doesn’t want its AI models to make the same mistakes twice.
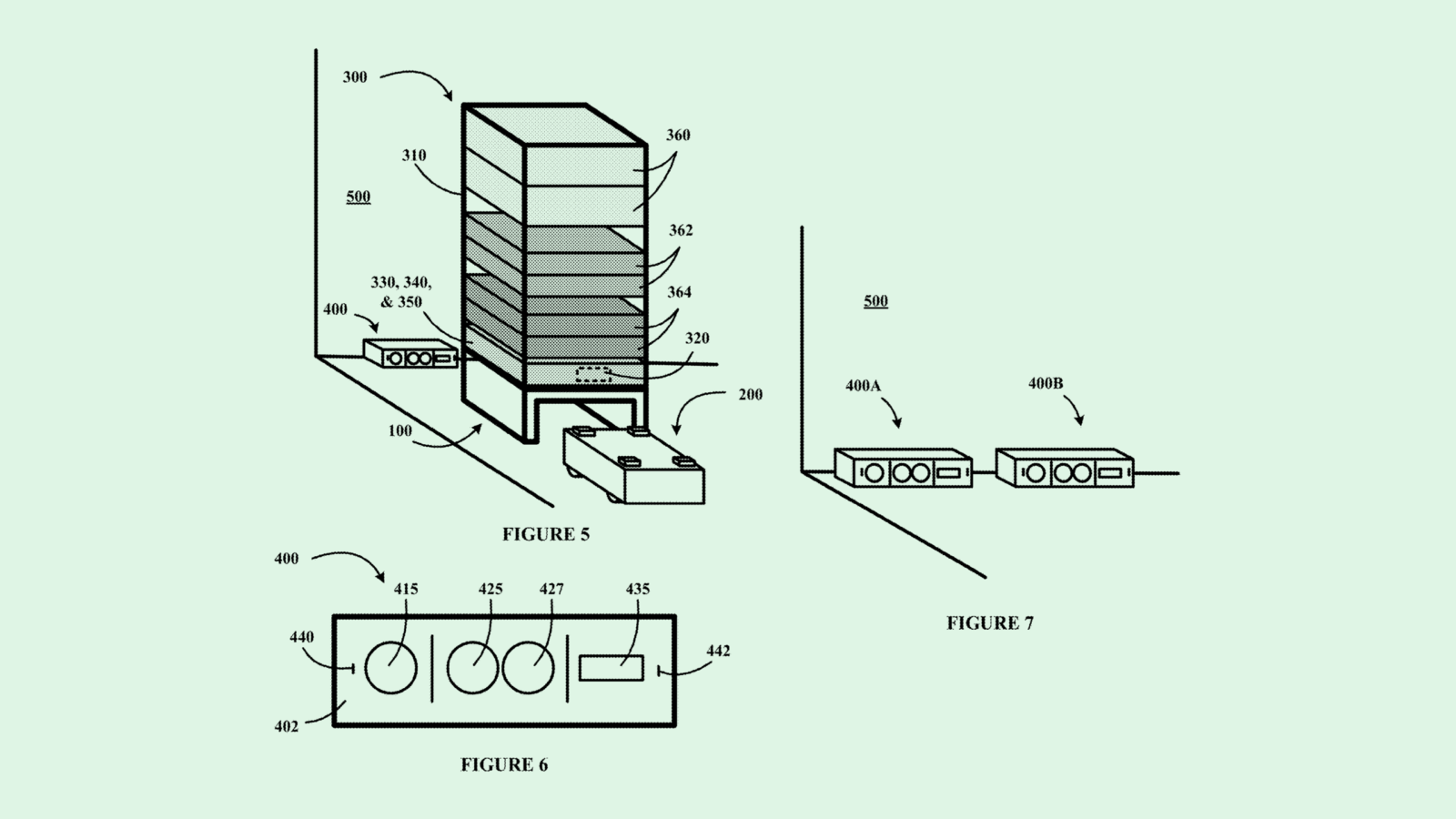
The tech giant filed a patent application for a way to train “on-device machine learning models” using corrections of automated assistant functions. Essentially, this tech creates a feedback mechanism that automatically trains both the AI models on a voice assistant device itself and adds to a global pot of training data for its voice assistants.
Voice assistants often include several different types of AI models, including “hotword detection models, continued conversation models, (and) hot-word free invocation models.” Google said its system aims to weed out “false negative determinations and false positive determinations” by any of these models, which can cause privacy concerns and lead to a waste of network and computational resources.
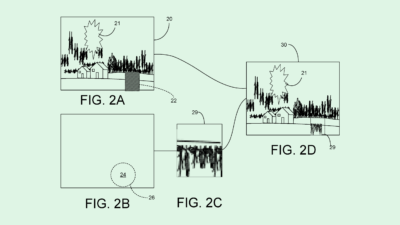
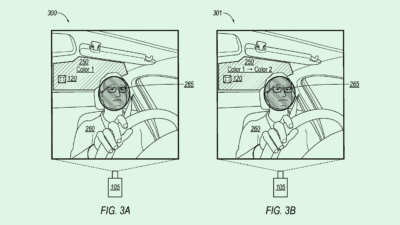
Google’s system aims to determine whether or not a dormant voice assistant was activated by accident: First, upon taking in environmental data, such as audio or other sensor data, a voice assistant would activate. Then, using a machine learning model, the system would figure out whether it was supposed to be activated or not.
For example, in a false-positive scenario, if a person says a wake word, like “Hey, Google,” in conversation with another person, a smart speaker may activate unnecessarily. In a false-negative scenario, the system may rely on a “hotword free invocation model,” but wouldn’t activate when a user requested it to.
If the model decides that the system was activated accidentally, the system develops a “gradient” comparing the output with the “ground truth output” — basically determining just exactly how wrong the system was in its false positive or false negative. That information is subsequently used to improve the device’s performance, as well as used to update a global speech recognition model “without any reference to or use of such data.”

While this patent specifically deals with accidental activations (or lack thereof), implementing a feedback mechanism of any kind into AI models used by the general public comes with inherent risks, said Brian P. Green, director of technology ethics at the Markkula Center for Applied Ethics at Santa Clara University.
Creating a large-scale model that’s strengthened with large amounts of data from users comes with privacy problems, said Green. Though Google notes that the gradients themselves would be transferred to the global model, rather than the speech data itself, users would need to be comfortable with their smart speaker interaction being used to train said models – or have the option to opt out.
Plus, communication norms, accents and language barriers are already present in speech recognition contexts, he noted. But this patent seemingly aims to mitigate that issue by collecting a larger dataset, Green noted.
“It’ll be interesting to see whether that (data) makes it lose specificity with other speech patterns or other other accents,” he said. “very often, (models) are very sensitive to things that we’re not necessarily anticipating them being sensitive to.”
Google has long been plugging away at making its speech recognition models more and more advanced. It launched an early voice recognition app in 2008, and jumped into the smart speaker market in 2016. Its patent activity proves that it’s only interested in making these models better.
So why are these companies so interested in training AI to understand the human voice? Verbal communication is something that almost every human has the capability to do, said Green. If tech firms can find a way for their devices to become part of the conversation, then that’s one more way that people are relying on their services, he said. “The goal of a user interface is to make the interface as easy as possible to use,” he noted.
But Google isn’t the only big tech firm that has spent years perfecting its speech recognition models. With Amazon integrating the large language models into Alexa, and Apple dropping the “hey” in “Hey Siri,” Google may be seeking to up its game.
Recent News
-
Google Patent Highlights AI and Quantum’s Symbiotic Relationship

Photo via U.S. Patent and Trademark Office

-

Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office



-
Microsoft’s Cybersecurity Strength Could Boost AI Bet
Photo via U.S. Patent and Trademark Office

-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office


-
Nvidia May Take Humans out of the Data Center Equation
Photo via U.S. Patent and Trademark Office
-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office