Google is Adding Empathy to it’s Smart Speakers
Google’s patent follows several updates from major tech companies aiming to understand emotions and context through speech recognition.

Sign up to uncover the latest in emerging technology.
Google wants its voice assistants to think before they speak.
The company filed a patent application for a voice assistant capable of “emotionally intelligent responses” to questions. To put it simply, along with identifying a user’s request, Google’s tech also attempts to determine a user’s emotions, and modifies its response based on that.
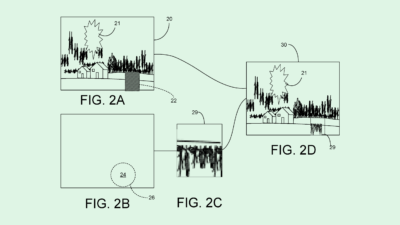
Google’s system first collects audio data after hearing a wake word to determine what query a user has using a speech recognition model (like any average voice assistant does). The system then performs what Google calls “query interpretation” on the transcription of the user’s voice command to determine the emotional state, as well as the severity of that emotional state. The system also determines whether or not the user’s emotional state “indicates an emotional need,” or needs to be addressed at all.
Along with performing the action that the user has requested, Google’s system tacks on a preamble to its response, depending on how the assistant determines a user is feeling. To generate this preamble, Google noted that its system may pull them from a database of pre-written phrases or use a “preamble generator” that uses the emotional state as input and writes a preamble as output.
For example, if a user says “Google, I fell down my stairs and hurt myself, how far is the nearest hospital?” Google’s system will respond with “try to stay calm” as a preamble, then answer the request and call the user’s emergency contact. Or if a user asks, “I am stressed, are there any anxiety support groups in the area?” the system may start with “I’m sorry to hear that,” before jumping into a response.

This patent adds to several from Google that aim to make its voice recognition tech better. The company has sought patents for tech enabling natural conversations using “soft endpointing,” as well as patents for a system to drop the “Hey Google” hotword that relies on lots of user monitoring.
But Google isn’t the only one wanting to make voice recognition less clunky: Amazon just announced an upcoming update to its Alexa smart speaker to make it sound more natural by making its voice sound less robotic and picking up on the tone and emotions in a user’s voice (FYI, Patent Drop featured a similar invention from Amazon earlier this year).
And Apple’s latest iOS, released last week, includes new Siri features to make conversation flow better, including nixing the “hey” in “Hey, Siri,” allowing back-to-back requests, and adding new languages to mixed-language conversation.
These companies’ interest in promoting naturally flowing conversation between users and their smart speakers could have a few motivations. For one, if users feel more comfortable relying on their smart assistants for day-to-day tasks and natural conversations, adoption (and sales) are likely to rise. However, the more users talk with their speakers, the more personal user data those speakers can collect. And for Big Tech firms, data is practically akin to money itself.
But the more that these companies push the boundaries with context and emotion in speech recognition, the more likely they are to run into the limitations of speech recognition models. Teaching an AI model to understand the emotions in a person’s voice or behind their words is no easy task. Adding in regional and cultural differences in communication norms only serves to compound this issue.
However, what Google’s system may have going for it is simplicity, as it monitors transcripts and pulls our pre-set or generated phrases of comfort based on keywords like “stress” or “hurt.” If only it was that easy for humans to understand one another.
Recent News
-
Google Patent Highlights AI and Quantum’s Symbiotic Relationship

Photo via U.S. Patent and Trademark Office

-

Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office



-
Microsoft’s Cybersecurity Strength Could Boost AI Bet
Photo via U.S. Patent and Trademark Office

-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office


-
Nvidia May Take Humans out of the Data Center Equation
Photo via U.S. Patent and Trademark Office
-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office