Microsoft Data Patent Walks the Line of Privacy Versus Nuance in AI Training
Though keeping privacy front-of-mind could help avoid AI-related data breaches, balancing privacy and nuance in data may be tricky.
Sign up to uncover the latest in emerging technology.
In AI development, data can be a double-edged sword. Microsoft may be looking at safety precautions.
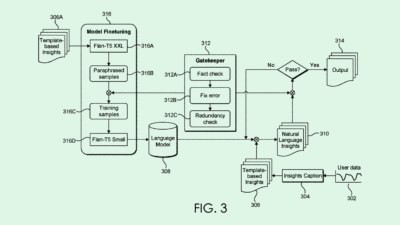
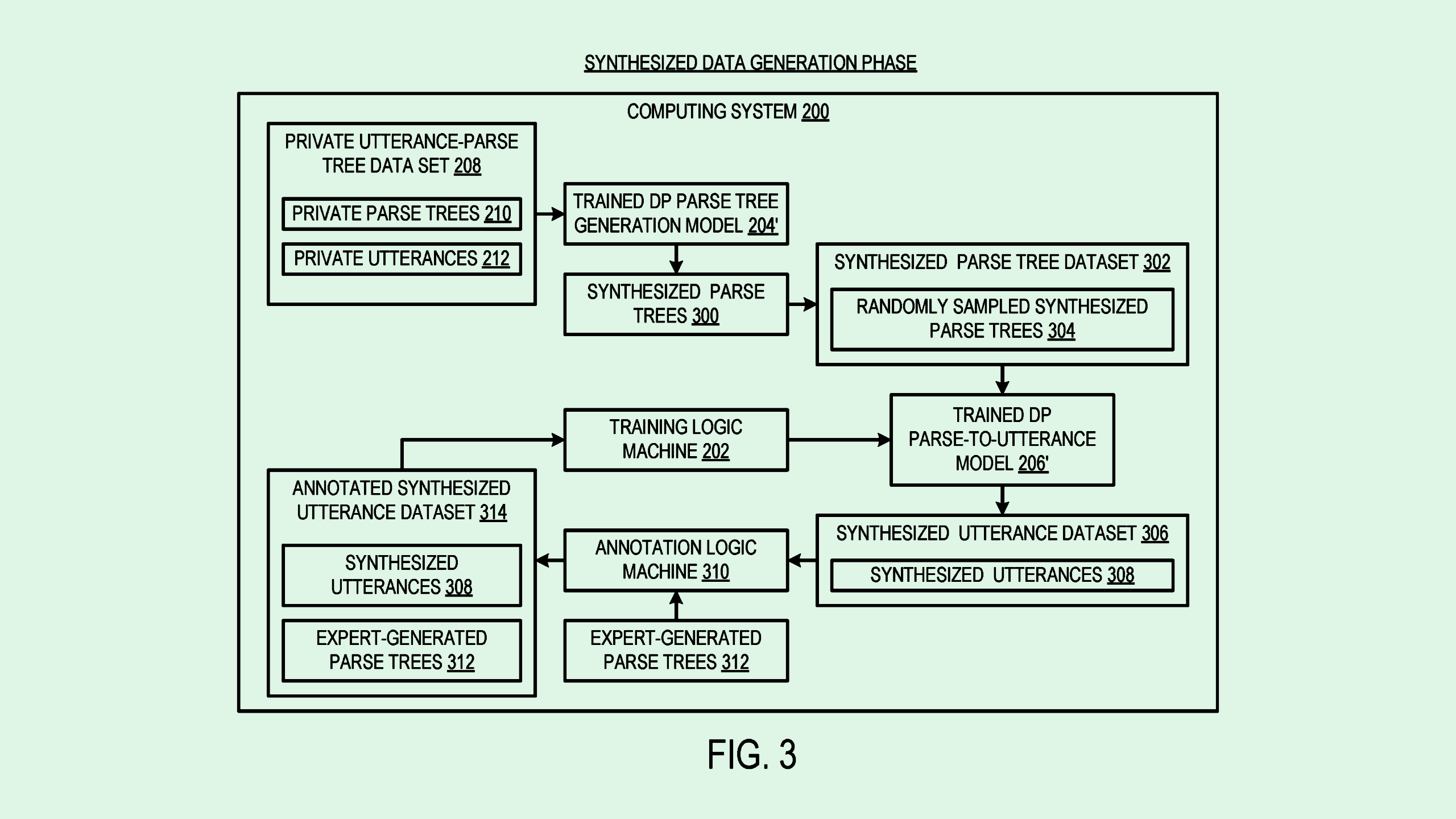
The company filed a patent application for a “privacy preserving generation” of synthetic training data — specifically “utterances,” or voice data. Microsoft’s tech aims to create robust datasets to train natural language processing and dialog models, such as speech recognition tools, without violating privacy.
This system first trains a generative model on a “differentially private” dataset of voice data. For reference, differential privacy is a technique in which noise is introduced to a dataset, essentially blurring out private information so that individual contributions aren’t revealed.
After learning from already-private datasets, the trained generative model is in turn used to create synthetic datasets. This process effectively provides two layers of protection: one from the initial training on differentially private data, and another from the use of synthetic data itself.
The synthetic data generated by this model can be used by developers without fear that their creations may accidentally spill private data, Microsoft said, as “trained models can ‘memorize’ details of their training data, which can be exploited through different types of attacks.”
AI models’ hunger for data comes with a host of privacy and security risks, said Bob Rogers, Ph.D., co-founder of BeeKeeperAI and CEO of Oii.ai. Microsoft’s patent takes two known solutions — synthetic data and differential privacy — and stacks them on top of one another.
While this could provide an extra barrier against an AI model leaking sensitive data, it also walks the line of the data losing its efficacy, said Rogers. The trade-off with privacy-forward synthetic data is less “expressiveness,” or the nuance and depth that help make an AI model more robust, said Rogers. In this case, balancing privacy and nuance may be tricky, he noted, but not impossible.
Having a privacy-forward mindset could stand to benefit Microsoft as it continues to plug away at developing models. As tech firms rapidly rush to dish out new AI tools and chase the spotlight with ever-growing large language models, something’s bound to give, Rogers said. In the event of a massive data breach, “you don’t want to be the company responsible.”
“You want to do what you can to avoid obvious things that would create a backlash against this thing that you’ve invested so much money in, and that you’re betting a lot of the future of the company on,” said Rogers.
Recent News
-
Google Patent Highlights AI and Quantum’s Symbiotic Relationship

Photo via U.S. Patent and Trademark Office

-

Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office



-
Microsoft’s Cybersecurity Strength Could Boost AI Bet
Photo via U.S. Patent and Trademark Office

-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office


-
Nvidia May Take Humans out of the Data Center Equation
Photo via U.S. Patent and Trademark Office
-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office