Salesforce Wants an AI That Can do it All
Salesforce’s patent for a multi-talented AI assistant signals that language models need to be more than just chatbots to be useful.
Sign up to uncover the latest in emerging technology.
Salesforce doesn’t want its AI models to be all talk.
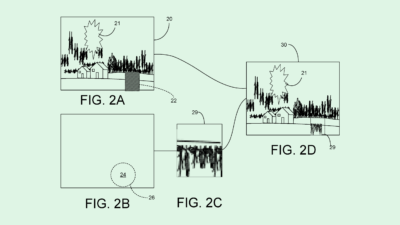
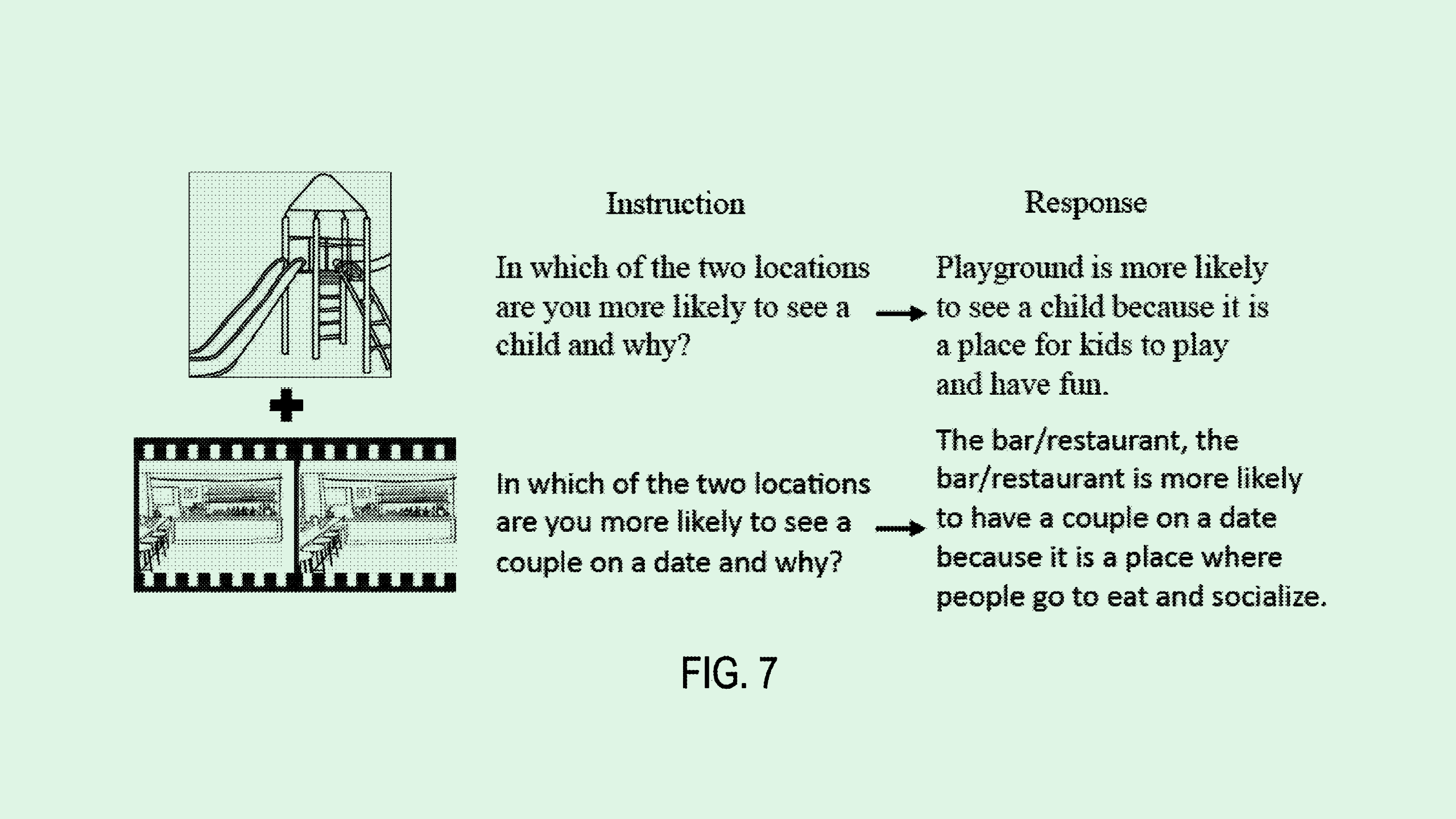
The company is seeking to patent a system for “multi-modal language models.” For reference, a multi-modal AI model is one that can handle input of multiple different kinds of data, such as text, audio, video and images, rather than just one.
“Existing systems may be designed for a single modality in addition to a text prompt (e.g., images), therefore there is a need for systems and methods for multi-modal language models for responding to instructions,” Salesforce said in the filing.
To achieve this, each type of data would get its own “specialized multimodal encoder” that turns it into something that the language model can comprehend. For example, video input would go through a video encoder, while audio input would go through an audio encoder.
These processed inputs, as well as whatever text prompt or request that the user sent alongside the initial data, are fed to a neural network-based language model. The model then interprets that data and generates an output, which could include any kind of data, not just text.
For example, a user could submit a video of a speech and request that this system summarize the main points. Or, a user could send in a script and ask that it be turned into an audio file.
Making an AI model that can understand multiple kinds of data is a formidable task. These models tend to be data intensive, compute intensive, necessitate tedious labeling, and generally require “more dimensions to understand context,” said Bob Rogers, Ph.D., the co-founder of BeeKeeperAI and CEO of Oii.ai. “I don’t think it’s easy.”
But the potential payoff is huge, said Rogers. For enterprises, a model with a deeper understanding of context can potentially automate the most tedious tasks and boost productivity for any industry, from finance to logistics to creative.
Multimodal AI is a focus of many of the major AI firms. OpenAI debuted multimodal capabilities in GPT-4o in May, with a model that can “reason across audio, vision, and text in real time,” said Rogers. Google’s Gemini language model also has multimodal capabilities, and Microsoft recently unveiled multimodal skills for Copilot.
It stands to reason that Salesforce is following suit, said Rogers, especially with its recent focus on AI agents. The company’s Dreamforce event largely focused on the promise of customizable agents that can operate across enterprises, with CEO Marc Benioff calling these models the “third wave of AI.”
But if Salesforce wants to keep up with the rest of tech and make something actually useful, these models may need to be more than just chatbots, said Rogers. “Otherwise, it would just be a bunch of iffy text chat bot interactions that are automating my work by giving me advice, when what I really want it to do is create,” he said.
“I think that’s where they’re headed, really letting [agents] automate all the steps,” he added. “But for the agents to do everything, that agent has to be multimodal.”
Recent News
-
Google Patent Highlights AI and Quantum’s Symbiotic Relationship

Photo via U.S. Patent and Trademark Office

-

Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office



-
Microsoft’s Cybersecurity Strength Could Boost AI Bet
Photo via U.S. Patent and Trademark Office

-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office


-
Nvidia May Take Humans out of the Data Center Equation
Photo via U.S. Patent and Trademark Office
-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office