Adobe Brings AI to DEI with Latest Patent
Adobe’s filing leaves a lot of unanswered questions, one expert told Patent Drop.

Sign up to uncover the latest in emerging technology.
Adobe wants to add some AI into diversity, equity, and inclusion. What could go wrong?
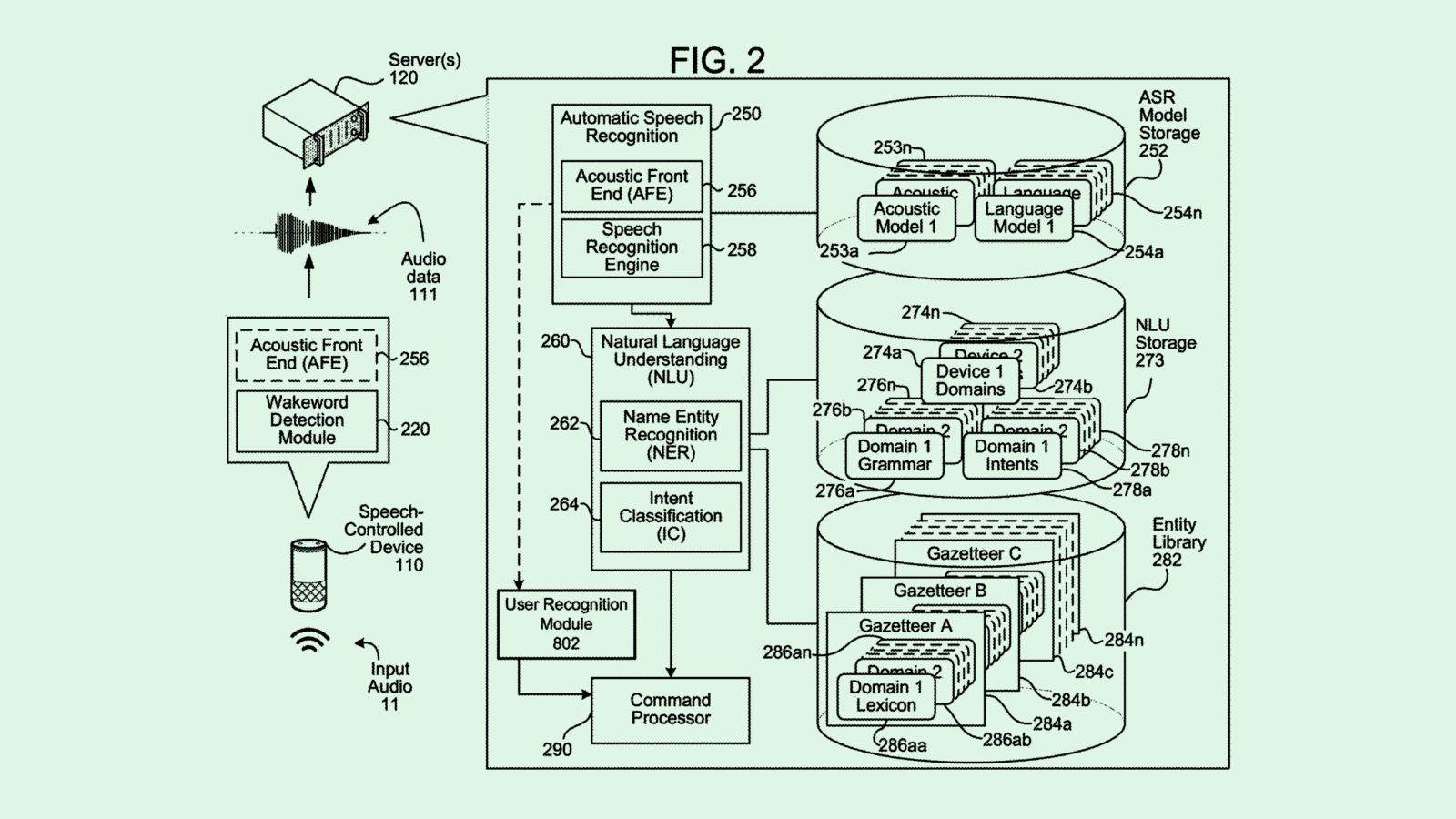
The company is seeking to patent a system for “diversity auditing” using computer vision. Essentially, this system uses facial detection and image classification to break down photos of employees and slot them into categories based on certain physical traits and characteristics.
Adobe’s system looks through several images and detects faces in each one, then classifies each face based on a predicted “sensitive attribute” relating to “protected classes of individuals,” such as race, age or gender. For example, Adobe noted, this system may classify images from a company’s website, then compare its predictions to a “comparison population.” (Adobe noted that this could mean census or employment data, but it could also potentially include internal data, such as a companywide diversity report.)
The system then calculates a “diversity score” for the set of images using machine learning by comparing the classified images to the comparison population. Finally, the system then “augments the set of images to increase diversity” using “additional retrieved images” until a certain threshold of diversity is met.
Adobe noted that conventional diversity auditing systems are time-consuming and “rely on manual identification of image attributes, and this manual approach does not scale to large image sets.”

Adobe’s intentions are seemingly in the right place, but potential problems exist with a system like this, said Mukul Dhankhar, founder at computer vision firm Mashgin. For starters, measuring diversity from photos is a difficult task. Can you really tell someone’s age, gender or ethnicity just by looking at them? How does this account for people of multiple races, or gender-nonconforming individuals? Those questions are left unanswered in the filing, Dhankhar noted.
“They talk about a single diversity score, but generally, diversity has multiple dimensions,” said Dhankhar. For example, he said, if you have a set of images that “represent multiple ethnicities, but they’re all male, would the model say that’s diverse? Or what if it takes in images of stereotypes? Those are some of the things that need to be taken into account.”
Adobe also has to be sure that the AI model itself was created without biases, as the biases of the person that built it can often translate to the outputs of the model itself unintentionally. “They don’t go into detail on how they will make this model or algorithm unbiased itself,” Dhankhar said.
However, there are potential good use cases for this technology if it’s done right, said Dhankhar. For example, this system could be used for checking if the data that’s used to train AI models is diverse enough. And if expanded beyond images into textual data, the use cases stretch even further.
“In general, the idea of identifying data set bias is a good thing,” he said. “But unfortunately, this patent doesn’t go into very many details.”
Recent News
-
Amazon Tries to Help Alexa Get Personal

Photo via U.S. Patent and Trademark Office
-

Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office


-
Snap Boosts Digital Ad Platform to Compete with Meta, TikTok
Photo via U.S. Patent and Trademark Office
-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office
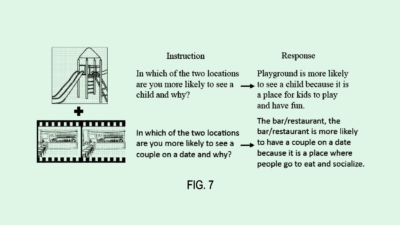
-
IBM May Pay Closer Attention to AI Risk Amid Model Boom
Photo via U.S. Patent and Trademark Office
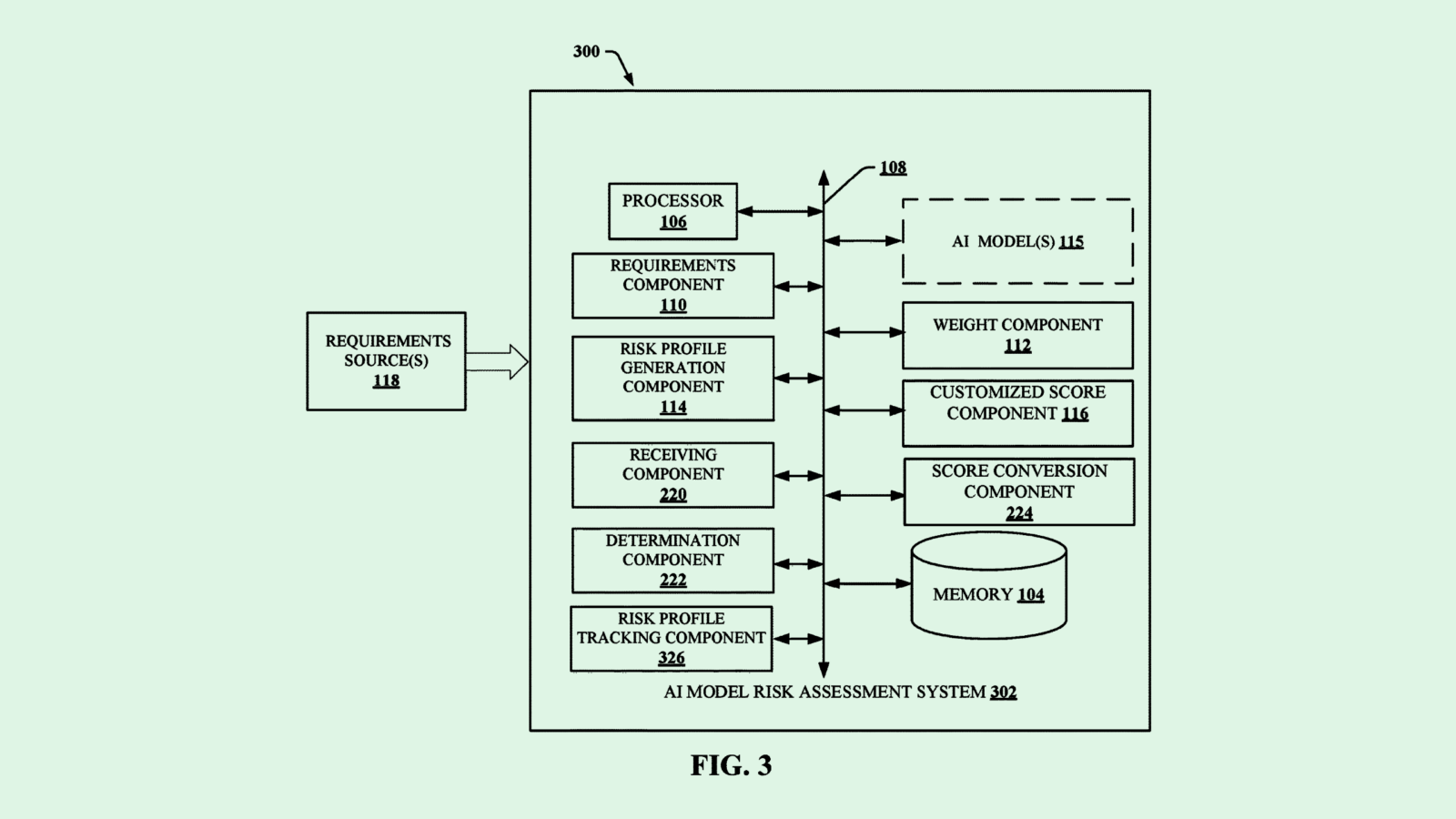
-
Photo via U.S. Patent and Trademark Office