Adobe’s Latest Patent Aims to Keep AI From Making Mistakes
“Real solutions to hallucination are going to be the next step change in AI.”
Sign up to uncover the latest in emerging technology.
AI “hallucination” has long stumped developers. Adobe may have found a way to minimize it.
The company is seeking to patent “text simplification with minimal hallucination.” The term refers to when a generative model makes up responses that are inaccurate due to a lack of proper training data. Adobe’s tech aims to break down complex text into small bits while keeping a model from throwing in incorrect statements.
When a model summarizes text, “hallucinations can include new and or inconsistent information with respect to the original text,” Adobe noted. “Such inconsistent information can carry significant consequences in areas such as legal documents and medical documents.”
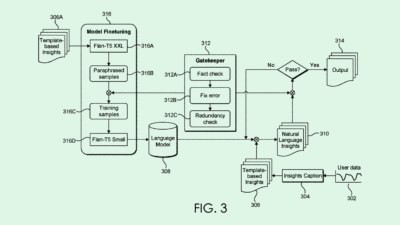
When Adobe’s summarizing neural network is fed a complex body of text to break down, it is assigned what the filing calls an “entailment score” for each sentence of the summary. This score indicates how well the simplified text corresponds to the complex text it was originally fed.
This score is determined by two main factors: “semantic similarity,” or whether or not any phrases are directly ripped from the complex text, and “hallucination scoring,” or the number of incorrect facts the model included in the summary. If the model’s summarized text does not receive a passing grade, it’s modified using a “pruning component,” which essentially strips the summary of any made-up phrases or redundant text.
Adobe says this text summarizer is configured to “operate without domain-specific training data.” This means that its system can theoretically summarize any category of text, whether it be medical documents, financial filings, or scientific papers, with minimal mistakes.
Even the most competent language models and AI developers struggle with hallucination, said Bob Rogers, PhD, co-founder of BeeKeeperAI and CEO of Oii.ai. OpenAI’s GPT-4 has a hallucination rate of around 3%, whereas other models have around a 5% rate, Rogers noted.
This is because language models often consider the linguistic flow of the text and the correlations between the words they’re writing over the facts themselves, Rogers said. Fact and flow are often only “loosely connected” in these foundational models. “Right now, (language models) really know a lot about how language flows and what linguistic clues lead to word choices,” he said.
While a 3% error rate doesn’t sound like a big deal, it depends on the context in which the model is used. In Adobe’s case, the company’s mastery of both creative and document-related technology could give a summarization tool like this a wide array of use cases.
In creative contexts, the error rate may not be as big of a deal. But if Adobe aims to implement AI tools in a more broad professional context, encompassing fields like medicine, finance, or government, a margin of error that wide is “kind of fatal,” said Rogers. “For a lot of use cases, — medical, financial, legal, national security even — a 3% error rate or hallucination rate is really not safe.”
However, Adobe’s proposed method of catching errors after the copy is created may be an “uphill battle,” Rogers said, as Adobe’s system may not catch when a summary includes information from the original complex text but is still incorrect. Additionally, Adobe’s tool being aimed at summarization makes this even harder, as pulling directly from a body of text, rather than rephrasing, leaves little room for error.
In reality, Rogers said, the best way to tackle these errors is by going back to the drawing board and training AI to connect fact and language. “Once that sort of understanding of facts sort of becomes more embedded in these foundational models, they’re going to be a lot smarter,” Rogers said. “Real solutions to hallucination are going to be the next step change in AI.”
Recent News
-
Google Patent Highlights AI and Quantum’s Symbiotic Relationship

Photo via U.S. Patent and Trademark Office

-

Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office



-
Microsoft’s Cybersecurity Strength Could Boost AI Bet
Photo via U.S. Patent and Trademark Office

-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office


-
Snap Boosts Digital Ad Platform to Compete with Meta, TikTok
Photo via U.S. Patent and Trademark Office
-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office