Google May Use Radio Waves to Feed its AI Models
Google’s patent to scrape radio stations for AI training could provide a pool of useful data, though it may face a copyright dilemma.
Sign up to uncover the latest in emerging technology.
Google wants its AI models to listen to the radio.
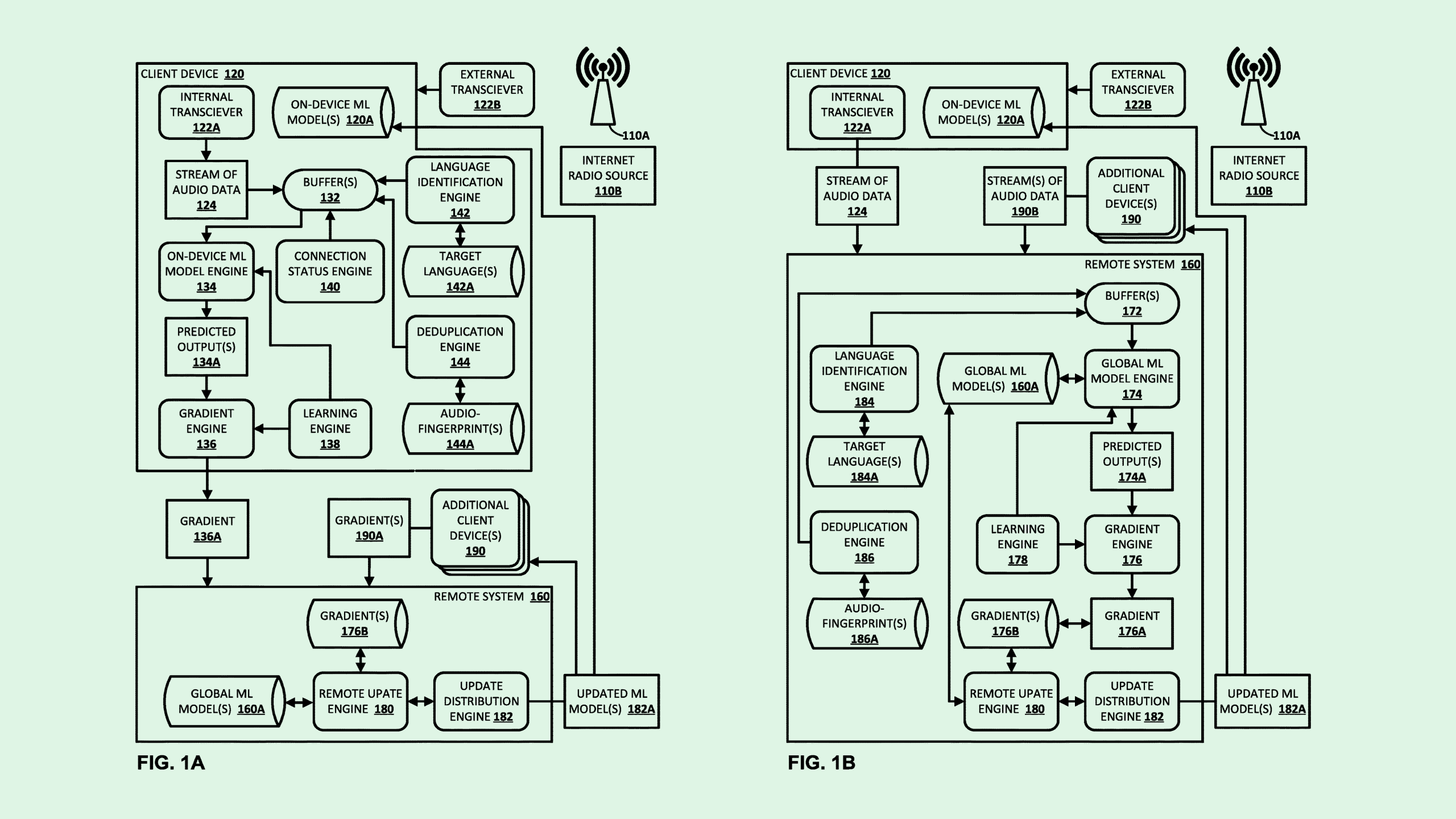
The company is seeking to patent a way to train machine learning models on radio station audio with “ephemeral learning and/or federated learning” Basically, Google’s system trains audio-based AI models on streams from tons of different radio stations around the globe.
Because publicly available speech data repositories may be limited, Google said in the filing that using radio streams will “expand the practicality of using these different ML techniques beyond explicit user inputs and … broaden the diversity of data utilized by these different ML techniques.”
This system allows machine learning models to learn less-common languages (Google calls these “tail languages”) via local radio stations. To keep these models from using the same audio streams over and over again – for example, if a commercial repeats once an hour – Google’s system employs “deduplication techniques” to remove those samples and prevent overfitting.
Google’s system relies on two kinds of machine learning techniques: federated and ephemeral. Federated learning is when a trained model is aggregated across a number of devices and servers, allowing the data to stay local to the device that collected it. Ephemeral learning is a subset of federated learning where the audio data is never stored by Google at all, but rather a continuous stream of data is simply used for training and then discarded.
Using these techniques, Google can constantly train and update audio-based models with the data of as many radio stations as it wants. The end result of all of this training is an ever-evolving model that can understand a wide range of phrases in many languages, even those that are “commonplace or well-defined,” making it more effective at responding to commands.
A major benefit of Google’s training method is the privacy-preserving element. For one, rather than getting audio data directly from users to train AI models, such as some of Google’s previous patents propose, this system uses voice data that’s already publicly available, thereby preserving user privacy. Plus, the use of federated and ephemeral learning keeps the audio data of those radio stations safe by never storing it within Google’s systems in the first place.
But there may be some privacy caveats that Google has to consider before training with a system like this, said Vinod Iyengar, VP of product and go-to-market at ThirdAI. If Google is wantonly drawing audio from radio stations globally, it may need to have a system in place for anonymizing that data, in case someone’s private information is shared on the radio.
“For example, let’s say someone’s phone number is mentioned on the broadcast … or names of people might be mentioned that they might want to remove,” Iyengar said. “Those are things that might be something that they should consider.”
And just because this data is publicly available doesn’t mean that Google won’t run into copyright pushback, Iyengar said. NPR, for example, notes that all of its content is covered by copyright protection, and must be cleared for use. And if this system takes in music as part of its data collection it opens another can of worms, as music use and licensing tends to be tightly regulated by labels.
The issue of fair use of data has been a hot topic in the advent of large language models, said Iyengar. A major example of this occurred in late December when The New York Times sued OpenAI and Microsoft for alleged copyright infringement related to the unauthorized use of the publication’s stories. OpenAI has since been sued by more media outlets.
In Google’s case, a problem could arise when this data is used to train AI models that the company makes revenue from, and that revenue isn’t shared with the original data source, said Iyengar. This is especially true if Google has nowhere else to get that data, such as training a speech model to understand local dialects where little data is available.
“These radio broadcasts are coming from underrepresented languages,” said Iyengar. “If I were Google, I’d be proactively trying to at least share some of the pie and give them some royalties or share revenues.”
Recent News
-
Google Patent Highlights AI and Quantum’s Symbiotic Relationship

Photo via U.S. Patent and Trademark Office

-

Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office



-
Microsoft’s Cybersecurity Strength Could Boost AI Bet
Photo via U.S. Patent and Trademark Office

-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office


-
Nvidia May Take Humans out of the Data Center Equation
Photo via U.S. Patent and Trademark Office
-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office