Google Wants to Clean Up its Data to Train AI Safely
Avoiding data security slip-ups involving its AI tools is vital in keeping its strong position in the market.

Sign up to uncover the latest in emerging technology.
With the amount of AI projects that Google has in store, keeping its data spick-and-span is likely of high priority.
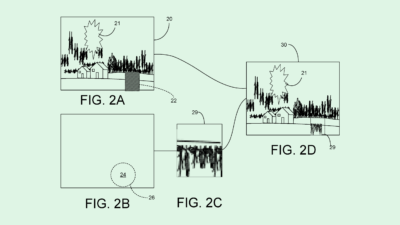
The company filed a patent application for a system for “anonymizing large scale datasets.” Google’s system aims to provide “improved privacy guarantees” to datasets that are “k-anonymous,” which specifically protects the identities of entities within a dataset.
K-anonymity is done as a “preprocessing step, such as prior to data release and/or prior to using the data for any potentially nonsecure purpose, such as for training a machine learning model (e.g. a deep neural network),” Google noted. This step can be vital in keeping personally identifiable data under wraps, such as medical and health data, or user data such as passwords or browsing history.
Google’s system assigns data to “entity clusters” that all share a common characteristic or reference a common entity. Once clustered, the system identifies a “majority condition” for each entity cluster, which determines what “data item” that most or all pieces of data within the cluster have in common. When the majority condition is discovered, the system assigns a “data item” to the entity it wants to anonymize in order to blur the common identifying thread.
Google said this system allows it to “selectively add or remove relationships in the data to anonymize the data” without compromising the integrity or structure of it. Google said in the filing that this method provides an alternative to “differential privacy” in datasets, which requires large changes to the structure of the data itself.

Google has been hard at work on AI development. The company has integrated AI throughout its workplace offerings, enhanced its search engine with AI, merged DeepMind and the Brain Team into one division, and has high hopes for its chatbot, Bard, to help the company reach two billion users, according to Reuters.
Plus, Google’s been filing patent applications for AI innovations at a near-constant clip, seeking to control everything from power-saving AI training methods to development automation tools to spam detection.
Given the fact that AI models are generally data-hungry, Google’s sheer access to data gives it a huge advantage. This is especially true given its privacy policy update from July which stated that the company has the right to scrape everything users post online to build its AI tools.
But because an AI model is only as good as the data that trains it, it’s also integral that the data it’s using is high-quality and doesn’t compromise user privacy. And because AI models can be reverse-engineered to spit out the data that they were trained on, making sure that data doesn’t contain personal user information is paramount.
A few solutions for the AI data privacy problem are in the works: Both Microsoft and Oracle recently filed patents for ways to prevent reverse engineering hacks and algorithmic attacks on models that could put their training data at risk. However, Google’s approach tackles the data itself, rather than the models, before it’s used to train AI systems in the first place. This approach of data minimization drastically limits user data vulnerability that any kind of data leak may present.
As the AI race heats up, Google has a lot riding on its work in the space. Avoiding data security slip-ups involving its AI tools is likely vital in keeping its strong position in the market.
Recent News
-
Google Patent Highlights AI and Quantum’s Symbiotic Relationship

Photo via U.S. Patent and Trademark Office

-

Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office



-
Microsoft’s Cybersecurity Strength Could Boost AI Bet
Photo via U.S. Patent and Trademark Office

-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office


-
Nvidia May Take Humans out of the Data Center Equation
Photo via U.S. Patent and Trademark Office
-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office