Google’s Latest Patent May Boost Enterprise AI Offerings
Google’s latest AI patent may make your spreadsheets less daunting.
Sign up to uncover the latest in emerging technology.
Google may want its language models to get comfortable with spreadsheets.
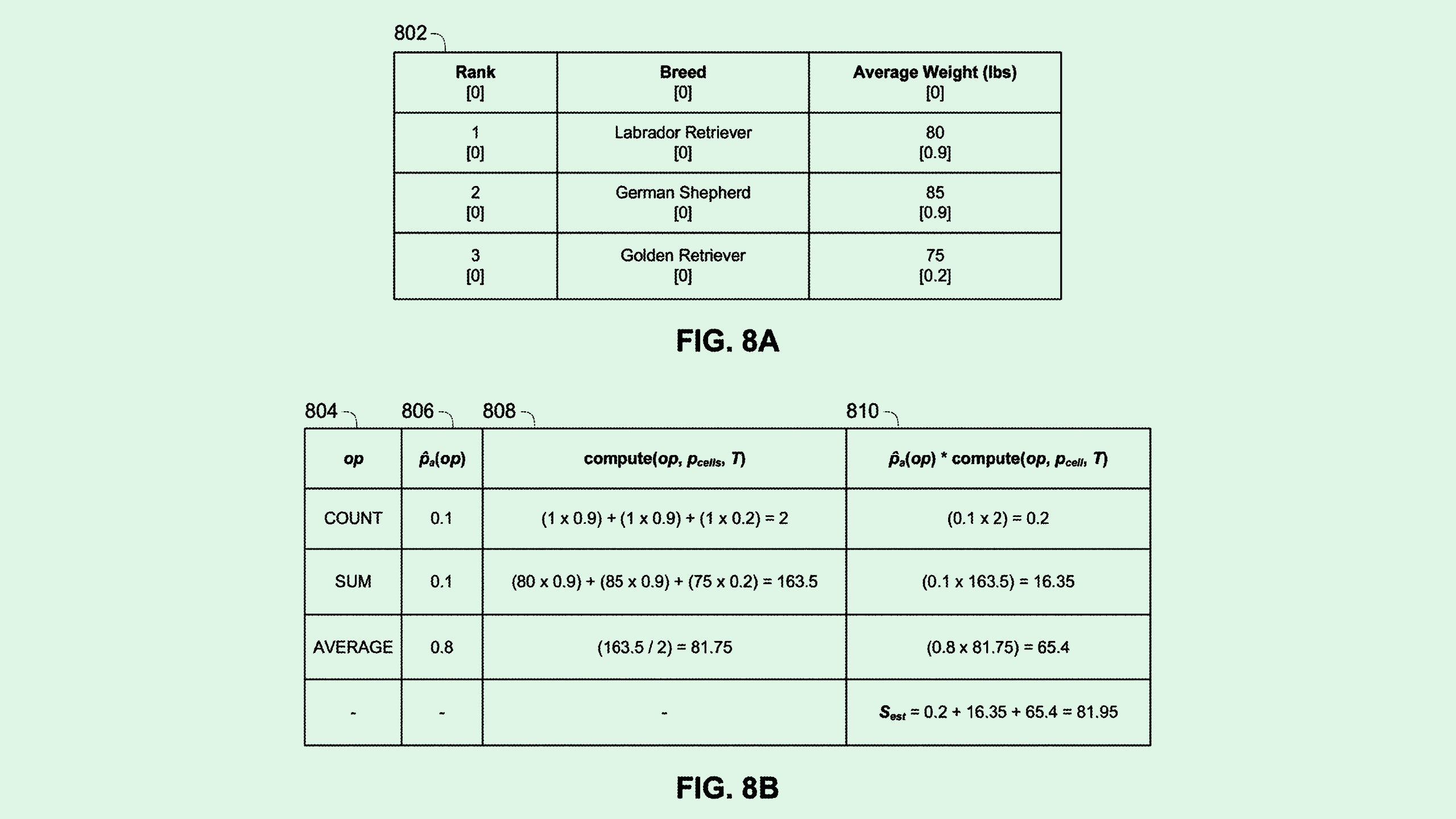
The company is seeking to patent a system for training language models to “reason over tables.” To put it simply, Google’s filing pitches a system that can train language models on a question-and-answer table without the use of “logical forms,” which are explicit representations of a natural language query that are easier for an AI model to understand.
Typically, training a model to accurately translate questions into these logical forms requires a good deal of human labor to create supervised training data, “making it expensive and difficult to obtain enough training data to sufficiently train a model,” Google said in the filing.
“Although an NLP model can, in theory, be trained to generate logical forms using weak supervision … such methods can result in the model generating forms which are spurious,” Google noted.
Google’s system first pre-trains a language model on synthetically generated tasks pulled from a large “unlabeled knowledge corpus,” or database like Wikipedia. Google’s system uses two methods of pre-training on this database: “masked-language modeling tasks,” in which the language model basically has to fill in word blanks of a sentence; and “counterfactual statements,” or “what-if” statements to help it understand relationships between data.
Following this, the language model is fine-tuned using examples derived from only a question, an answer, and a table. This fine-tuning essentially allows the model to apply what it’s learned in training to the specific data in front of it, allowing it to answer questions based just on data from those tables.
Though this may sound quite technical, the outcome is a more easily scalable and adaptable language model that has a simpler development process and can handle all kinds of data, structured or unstructured.
Google’s system relies on taking logical forms out of the process of AI training, which is already a pretty common concept in large language model development, said Vinod Iyengar, VP of product and go-to-market at ThirdAI. Where the value of this tech lies, however, is in its application specifically for breaking down large spreadsheets or documents filled with tables, and answering questions about them with little pre-processing needed.
With structured and unstructured data, “there’s work being done to handle each of those separately,” Iyengar said. “It becomes tricky when you have a mix of data. But Google’s claiming they can handle all of that easily.”
This kind of tech could be particularly valuable for enterprise purposes, said Iyengar. For example, if someone needs to quickly analyze a large financial document that’s filled with both structured and unstructured data, such as tables, figures, and paragraphs of text, a system like this could be trained to accurately answer queries related to it.
“The more they can automate this workflow instead of manually pre-processing all the data — if that can all be eliminated and LLMs can do it themselves — then that will be a huge win,” said Iyengar.
Google has spent the past year weaving AI throughout its Workplace suite and enhancing its search engine with AI. Its patent activity is filled with enterprise-related AI innovations, including automatic generative coding and design tools.
The company faces stiff competition with the tag team of OpenAI and Microsoft, which offers its own AI-based work and productivity suite with Copilot. But creating a system that can train models to parse through tons of different types of data only serves to bolster its enterprise offerings more. “They’re probably going to offer this more broadly as part of their AI stack,” Iyengar noted.
Plus, if this is integrated into Google Gemini, this could also be put to use in its potential partnership with Apple. For instance, a system like this could be paired with iCloud, allowing users to easily break down large documents within Apple’s systems.
Recent News
-
Google Patent Highlights AI and Quantum’s Symbiotic Relationship

Photo via U.S. Patent and Trademark Office

-

Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office



-
Microsoft’s Cybersecurity Strength Could Boost AI Bet
Photo via U.S. Patent and Trademark Office

-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office


-
Google May Be Giving Glasses Another Go. Will It Succeed?
Photo via U.S. Patent and Trademark Office
-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office