IBM Wants to Weed Out Falsely Advertised AI Tools
IBM’s tech could help AI services address the knowledge gap between consumers and the AI tools they use.
Sign up to uncover the latest in emerging technology.
IBM wants to instill some confidence in AI systems.
The company seeks to patent a way to measure “artificial intelligence trustworthiness” based on the front-end user experience. IBM’s system aims to help AI companies and services identify where they can be more transparent about their outputs.
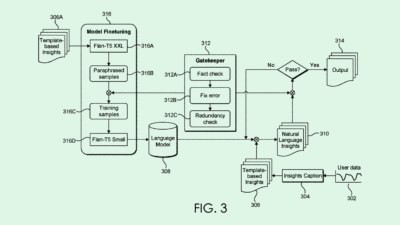
As AI becomes more advanced, so does the need for explainability, IBM noted. “Developers can help address this challenge by designing front-end (user experiences) … that provide explanations about how an AI model came to a decision,” IBM said. “However, it is often the case that a front-end UX simply provides a prediction output by an AI model with no further explanation.”
The system uses a machine learning algorithm to identify the parts of the user experience that convey information about its AI models. It then evaluates them to see if they meet certain thresholds of explainability, transparency, fairness, and “uncertainty quantification,” or a measure explaining how uncertain the AI model’s outputs may be.
The system then combines the different threshold scores to calculate an overall trustworthiness score for how the AI outcomes are explained. If a service falls below a certain threshold, IBM’s tech will recommend ways to fix its user experience.
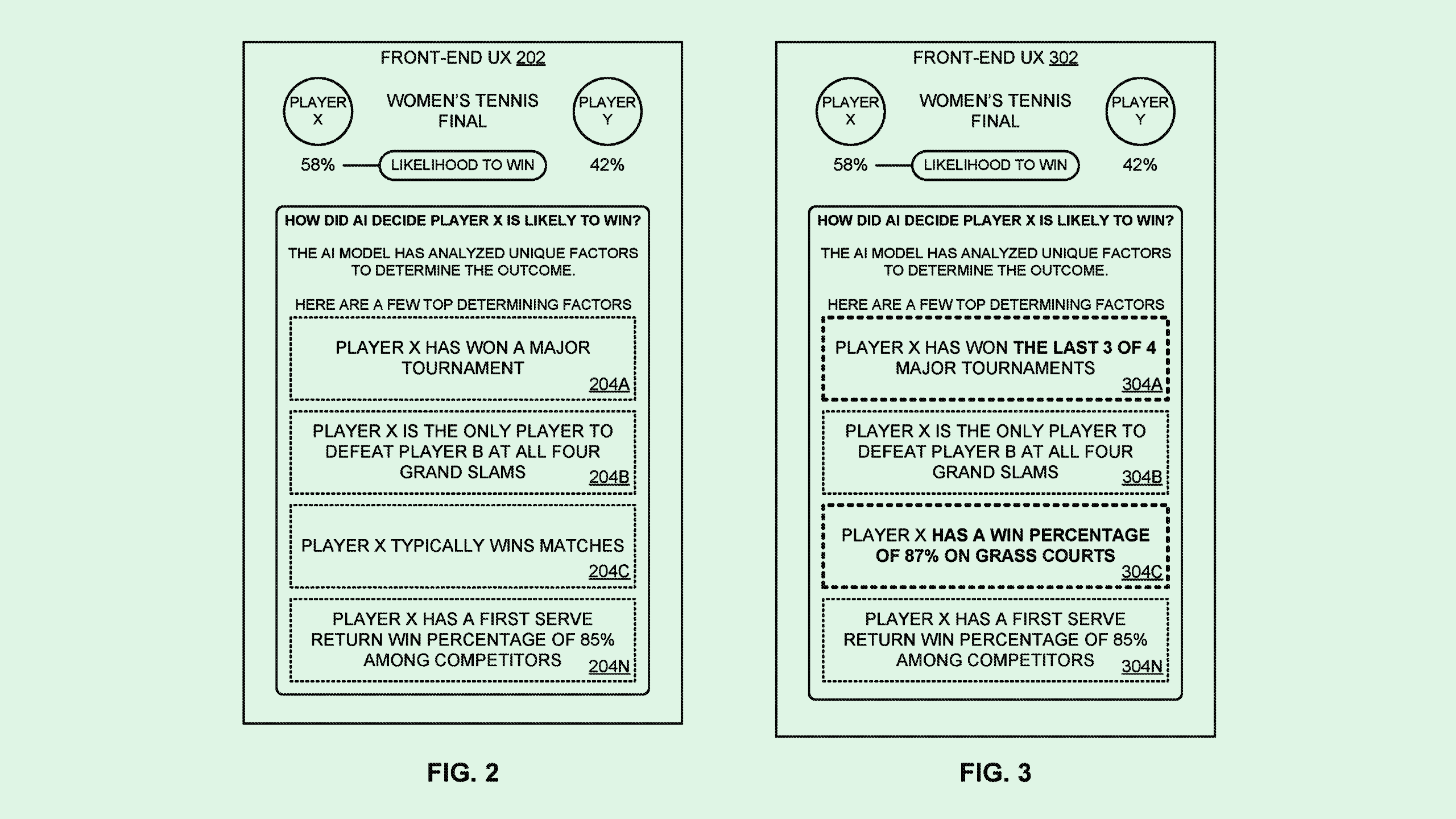
For example, if a website that predicts tennis match outcomes says it chose the predicted winner in a match because they typically win matches, IBMs system may opt to be a little more precise, changing the wording to “Player X has a win percentage of 87%.”
Gaining consumer trust isn’t always an easy thing, especially in tech. Big tech firms have abused users’ trust on numerous occasions by not treating their data with the privacy it deserves. And amid the AI boom, in which large-scale models created by these big tech firms are hungry for data, consumers are growing even more skeptical.
A survey last year of more than 5,000 Americans out of Bentley University and Gallup found that 79% of respondents didn’t trust companies to use AI responsibly. This distrust is why it’s vital for AI developers to be forthright about what’s going on behind the curtain, said Arti Raman, founder and CEO of AI data security company Portal26.
“As humans, we have an inherent distrust of automation and automated systems,” said Raman. “If businesses are able to win people to trust, then the competitive advantage and the productivity and value creation process is so much faster.”
There are a few potential avenues to win trust, Raman said. One is explainable AI, in which AI models aren’t stuck in so-called black boxes, but rather show how they arrive at their predictions. Another route is disclosing exactly what the AI model’s capabilities are — and what their capabilities aren’t — a service that IBM’s patent aims to offer.
“AI is a really complicated thing,” Raman said. “And I think that people don’t trust things they don’t understand.”
Finally, there’s the “old-fashioned seal of approval route,” said Raman. Creating oversight organizations that indicate which AI systems are ethical and safe could help consumers of AI products feel more comfortable.
However, consumers have every right to have a healthy skepticism of the AI they’re using. OpenAI, Google, and Microsoft have all faced data vulnerabilities relating to their massive AI operations. And if you use any big tech company service, that means you’re also likely helping train their AI inadvertently, said Raman.
“If AI is baked into my Google workspace, I am the product,” Raman said. “And I actually would very much like to know exactly how it’s working and have evidence of that.”
Recent News
-
Google Patent Highlights AI and Quantum’s Symbiotic Relationship

Photo via U.S. Patent and Trademark Office

-

Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office



-
Microsoft’s Cybersecurity Strength Could Boost AI Bet
Photo via U.S. Patent and Trademark Office

-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office


-
Snap Boosts Digital Ad Platform to Compete with Meta, TikTok
Photo via U.S. Patent and Trademark Office
-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office