Meta Patent Could Make AI Both Personalized and Private
Tech like this could keep Meta’s models from prompt attack data slips — or at least give it some “thought leadership brownie points.”
Sign up to uncover the latest in emerging technology.
As Meta attempts to keep up in AI, the company may want to get personal.
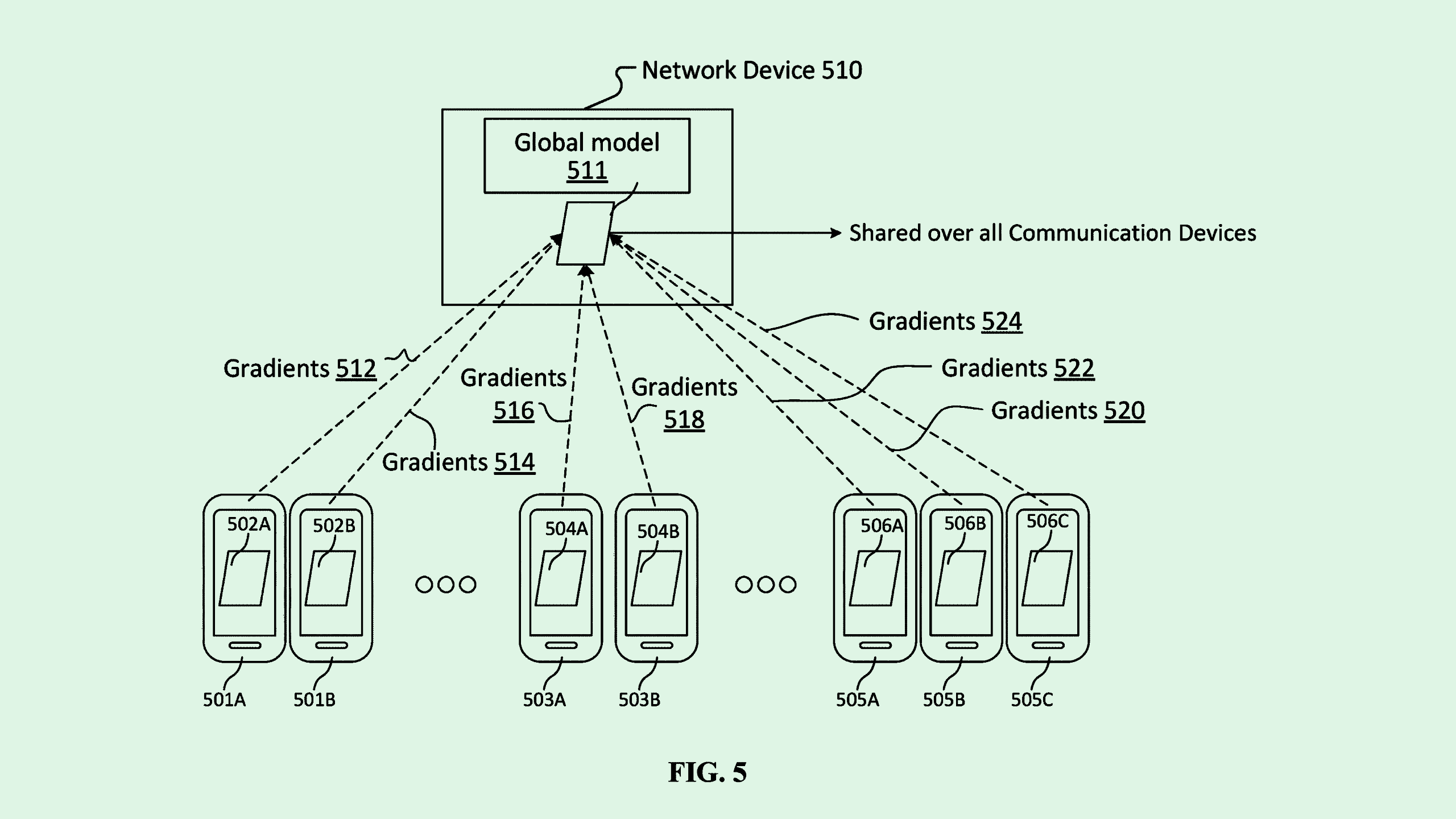
The social media giant filed a patent application for “group personalized federated learning.” Federated learning allows a global model to train locally on data from multiple devices without actually transferring that data from those devices.
However, the problem with this technique is that “typically, a majority of users only have a few training examples, making it challenging to improve the performance of a machine learning model for individual client devices,” Meta said in the filing.
To overcome this, rather than simply learning from each user, Meta’s tech uses federated learning techniques to group users’ models by their similarities.
When a global model is trained on local data from users’ devices, the trained model is sent back to a central server. The server analyzes the new models’ parameters to discover similar patterns to batch them together. Those batches are then used to create and deploy group-specific machine learning models customized to suit the characteristics — such as demographics or social media profile types — of each group. This allows Meta to train a model to be more robust without invading users’ privacy.
Federated learning is one of the most common forms of AI training, said Pakshi Rajan, VP of products and co-founder at AI data security company Portal26. While it’s helpful for training a global, general model without violating data privacy, Meta’s patent may present an improvement on this concept by allowing for localization and personalization, he said.
For example, if a self-driving car company is using federated learning to train its vehicles, this could help vehicles understand and apply local traffic laws. “My gut feel is that a lot of people are already doing this,” Rajan said.
In Meta’s case, there are several ways this can be useful. For starters, given that the company’s main cash cow is digital advertising, it could allow for personalized advertising based on profile demographics without compromising privacy. It could also help Meta personalize its AR experiences, Rajan noted, without necessarily exporting data from user headsets.
“Personalization can be done in such a way that the data can be sent without compromising the personal space of the person or the owner of the device,” said Rajan.
Meta, however, doesn’t necessarily have the best reputation for user privacy. And the company has acknowledged using all public user posts since 2007 (unless you’re in the EU) to train its models. Tech like this could keep its models from prompt attack data security slips — or at least give it some “thought leadership brownie points,” said Rajan.
Recent News
-
Google Patent Highlights AI and Quantum’s Symbiotic Relationship

Photo via U.S. Patent and Trademark Office

-

Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office



-
Microsoft’s Cybersecurity Strength Could Boost AI Bet
Photo via U.S. Patent and Trademark Office

-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office


-
Nvidia May Take Humans out of the Data Center Equation
Photo via U.S. Patent and Trademark Office
-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office