Microsoft May Want its AI Models to Speak to the Heart
Microsoft’s patent for a language model that talks back signals Big Tech’s interest in multimodal AI.
Sign up to uncover the latest in emerging technology.
Microsoft wants its language models to go a step further.
The tech firm wants to patent a system for “spoken natural stylistic conversations” with large language models. Microsoft’s tech aims to give language models the capability to carry our natural, emotionally expressive voice conversations with users.
“To enhance the user experience, enable broader applications, and empower more users to take advantage of large language models, there is a need for additional options for interfacing with large language models,” Microsoft said in the filing.
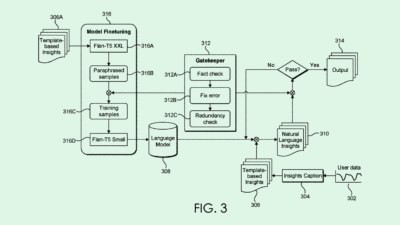
Microsoft’s system first converts user speech into text for the language model to understand it. This text then goes through a “prompt engine” for sentiment analysis to understand the emotional tone of the user’s request.
The large language model then responds to the user, first generating a text output and then converting it to a speech response with a text-to-speech engine. Microsoft’s tech also feeds “style cues” picked up from sentiment analysis to the engine, which adds inflection and emotion to the speech it generates, aiming to properly respond to the user’s emotional input. “In this way, a user can be immersed in a conversation that feels natural and lifelike,” Microsoft said.
For example, if a user asks this system “What is exciting about living in New York?” the system would pick up on the word “exciting,” and feed the speech-to-text engine style cues to express enthusiasm when answering the question.
Microsoft’s patent highlights how tech firms want their massive foundational AI models to serve as more than just chatbots. Companies are increasingly seeking to make their AI multimodal, or capable of understanding and responding in more than just text.
OpenAI recently dropped GPT-4o, its model capable of understanding audio, vision, and text in “real time.” Elon Musk’s xAI reportedly wants to allow multimodal inputs for its Grok chatbot, too. Google, meanwhile, debuted Project Astra at its I/O conference earlier this month, an AI assistant capable of understanding “the context you’re in.”
Adding multimodal inputs and outputs is a “factor of utility,” said Bob Rogers, PhD, co-founder of BeeKeeperAI and CEO of Oii.ai. “Our experience as humans is a multimodal, sensory experience – it’s how we take information in and respond back. It’s much richer and more effective than following a single track.”
And while Microsoft’s patent presents a simple solution for an AI model to understand users’ emotions a little better, it may be a bit too simple, said Rogers. The tech in this patent adds inflection based solely on the potential sentiment of the words themselves, not taking into account data that may be derived from the tone, he noted.
“The tech, I think, has some limitations,” he said. “The goal is sentiment analysis but the tech that they’re patenting here is not quite fit for purpose.”
However, leaving out the capability to comprehend audio could make for a much lighter-weight model, said Rogers. This limitation could benefit Microsoft if it aims to fit resource-intensive AI capabilities into smaller packages, such as with the company’s recently announced AI PC hitting the shelves in June. “It makes sense if they’re trying to make a less annoying Clippy,” Rogers noted.
Recent News
-
Google Patent Highlights AI and Quantum’s Symbiotic Relationship

Photo via U.S. Patent and Trademark Office

-

Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office



-
Microsoft’s Cybersecurity Strength Could Boost AI Bet
Photo via U.S. Patent and Trademark Office

-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office


-
Google May Be Giving Glasses Another Go. Will It Succeed?
Photo via U.S. Patent and Trademark Office
-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office