Microsoft Patent Could Broaden Large Language Models’ Horizons
Microsoft wants its language models to be a little more adaptable.
Sign up to uncover the latest in emerging technology.
Microsoft wants its AI models to pick up on subtleties.
The company is seeking to patent a system for “large language model utterance augmentation.” This aims to give a language model a broader understanding of user queries by understanding when certain phrases are “semantically related to one another.”
Conventional training of large language models is often tedious, as it involves “brainstorming complex regular expressions or curating massive, labeled datasets containing an exhaustive collection of possible utterances,” Microsoft noted. This patent aims to upend that process by helping models understand the intent of a user’s request, rather than just the words they’re saying.
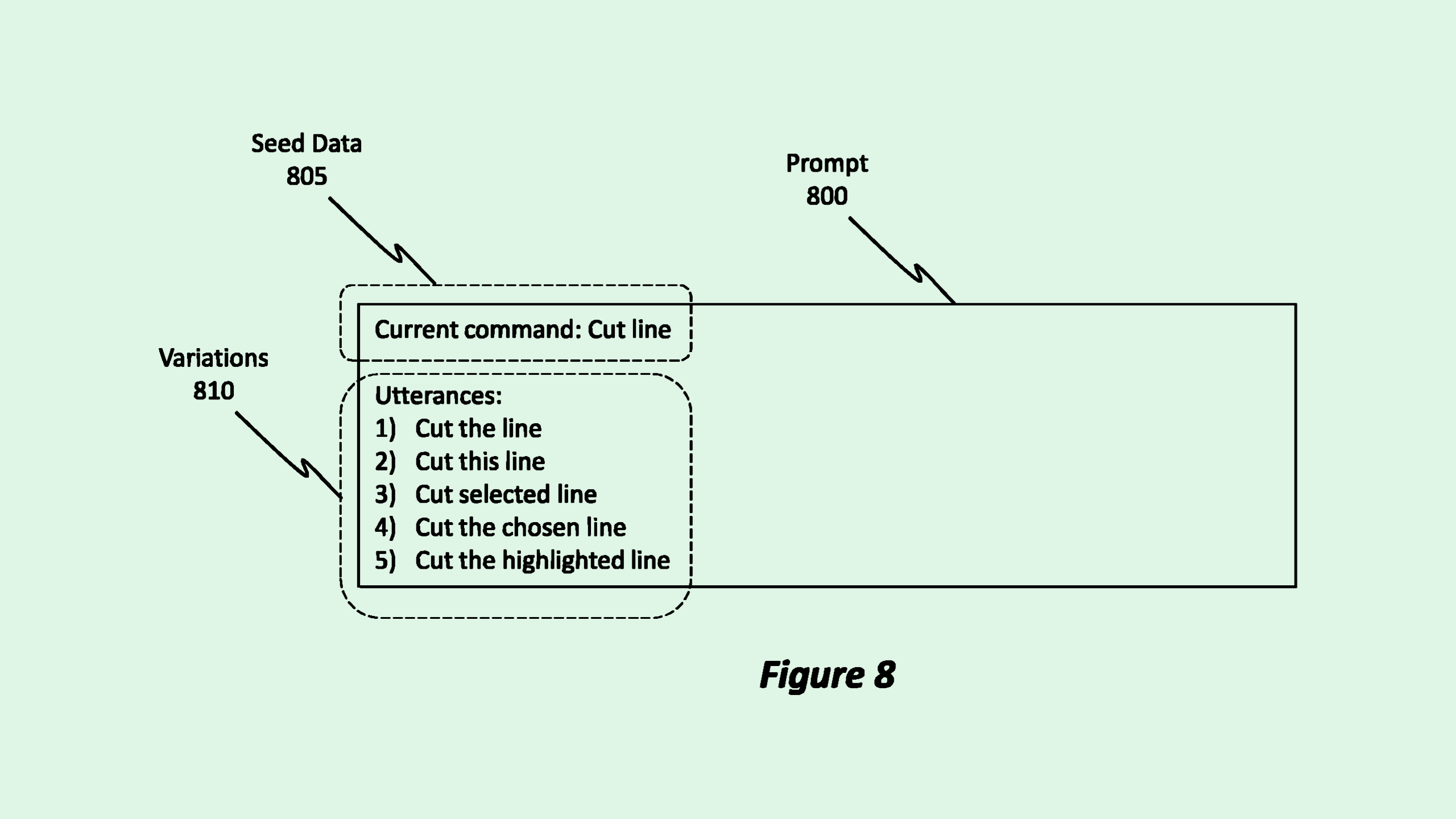
Microsoft’s system starts with a large language model trained on an “arbitrary corpus of language training data.” This system then feeds that language model “seed data,” which includes several phrases that are semantically linked together, such as variations of a certain phrase.
The language model takes that seed data and creates even more possible variations, broadening its scope. When any one of these phrases is later received as an input query by a user, the model understands it as linked to a group of phrases, triggering a specific command.
For instance, in the context of a voice-activated AI model, if you say “lower the music,” this system may link it to related phrases like “turn down the music” or “lower the volume,” and understand what to do. In the context of a chatbot or copilot, if you ask it to search for a certain file, but misspell the file name, it would be able to complete the request anyway.
For the past year, Microsoft has worked arm-in-arm with OpenAI on the development and integration of its large language model into several of its Copilot products. To date, Microsoft has invested $13 billion in the startup.
But the tech giant seems to be working on a large language model of its own. Last week, The Information reported that Microsoft is training a large language model called MAI-1, which can reportedly rival OpenAI’s GPT-4. The model’s development is being overseen by Mustafa Suleyman, co-founder of Google DeepMind and former CEO of AI startup Inflection.
The model is far larger than any of its current open source models at around 500 billion parameters (compared to OpenAI’s one trillion parameters) and is likely to be much more expensive, The Information noted. The company may debut this model at its Build conference on May 16.
While the company hasn’t clarified what it intends to use this model for, Microsoft CTO Kevin Scott took to Linkedin last week to say that its partnership with OpenAI isn’t likely to go away. “There’s no end in sight to the increasing impact that our work together will have,” Scott said.
And though little is publicly known about the company’s new AI, patents like these may give some insight into how it’s training and implementing its large language models.
Recent News
-
Google Patent Highlights AI and Quantum’s Symbiotic Relationship

Photo via U.S. Patent and Trademark Office

-

Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office



-
Microsoft’s Cybersecurity Strength Could Boost AI Bet
Photo via U.S. Patent and Trademark Office

-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office


-
Snap Boosts Digital Ad Platform to Compete with Meta, TikTok
Photo via U.S. Patent and Trademark Office
-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office