Microsoft Patent Protects AI Models from Data Security “Jailbreak”
Though there are a lot of ways to protect AI models, monitoring user behavior is a vital piece of the puzzle.
Sign up to uncover the latest in emerging technology.
If you don’t have anything nice to say, don’t say anything at all. At least not to chatbots.
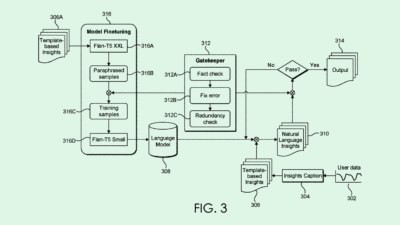
Microsoft filed a patent application for “adverse or malicious input mitigation for large language models.” The company’s filing details a system to prevent users from feeding a language model inputs that would elicit outputs that are inappropriate or present security risks.
The tech essentially aims to keep models from hallucinating and spitting out inaccurate answers, as well as avoid prompt injection attacks “in which user inputs contain attempts by users to cause the LLMs to output adverse (e.g., malicious, adversarial, off-topic, or other unwanted) results or attempts by users to ‘jailbreak’ LLMs.”
When a language model receives a malicious input, the system will pull similar pairs of bad inputs and their corresponding appropriate responses from a database of past interactions. Additionally, it may pick inputs that are similar to the conversation, but not malicious, so the model learns the difference between normal and inappropriate inputs.
Those similar pairs are incorporated into the language model’s input, essentially filtering user chats before they reach the language model. That way, the model has an example of how to correctly respond to a malicious input, and it’s dissuaded from answering in an unsafe way.
It makes sense why Microsoft would want to keep its models from spilling the beans. The company has spent the past year promoting its AI-powered work companion, Copilot, as a means of boosting productivity. And though it has a partnership with OpenAI, Microsoft is also developing its own language models, both large and small. As the AI race continues to tighten, any security breakdowns could be massively detrimental.
Though there are a lot of ways to protect AI models, monitoring user behavior is a vital piece of the puzzle, said Arti Raman, founder and CEO of AI data security company Portal26. Most malicious activity related to AI models comes from prompt-based attacks, she said. Because of this, these attacks are a major talking point among model developers and tech firms.
“There are different types of ways in which [large language models] can be attacked, and malicious users are a pretty important one,” said Raman. The problem is multiplied if a user’s prompts are used to further train a model, as the attack “lives on in perpetuity,” she said. “It becomes part of the model’s knowledge, and just creates an increasing and exploding problem.”
There are three primary ways to keep an AI model from leaking private sata, said Raman. First is by protecting the data pipeline itself, in which data security faults are intercepted before they reach the model. The second, demonstrated in Microsoft’s patent, is using pattern recognition and user monitoring to mitigate attacks in real time. The third is identifying commonly-used malicious prompts and robustly protecting against them.
The best approach, especially as AI development and deployment reaches a fever pitch, is a combination of the three, she said. “We should throw everything we have at the problem so we make sure that our pipelines are protected up front,” Raman said.
Recent News
-
Google Patent Highlights AI and Quantum’s Symbiotic Relationship

Photo via U.S. Patent and Trademark Office

-

Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office



-
Microsoft’s Cybersecurity Strength Could Boost AI Bet
Photo via U.S. Patent and Trademark Office

-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office


-
Google May Be Giving Glasses Another Go. Will It Succeed?
Photo via U.S. Patent and Trademark Office
-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office