Intel Patent Addresses Privacy Pitfalls in Federated AI Models
Intel wants to protect personal data in the Internet-of-Things.
Sign up to uncover the latest in emerging technology.
Intel wants to make sure that AI training data is under lock and key.
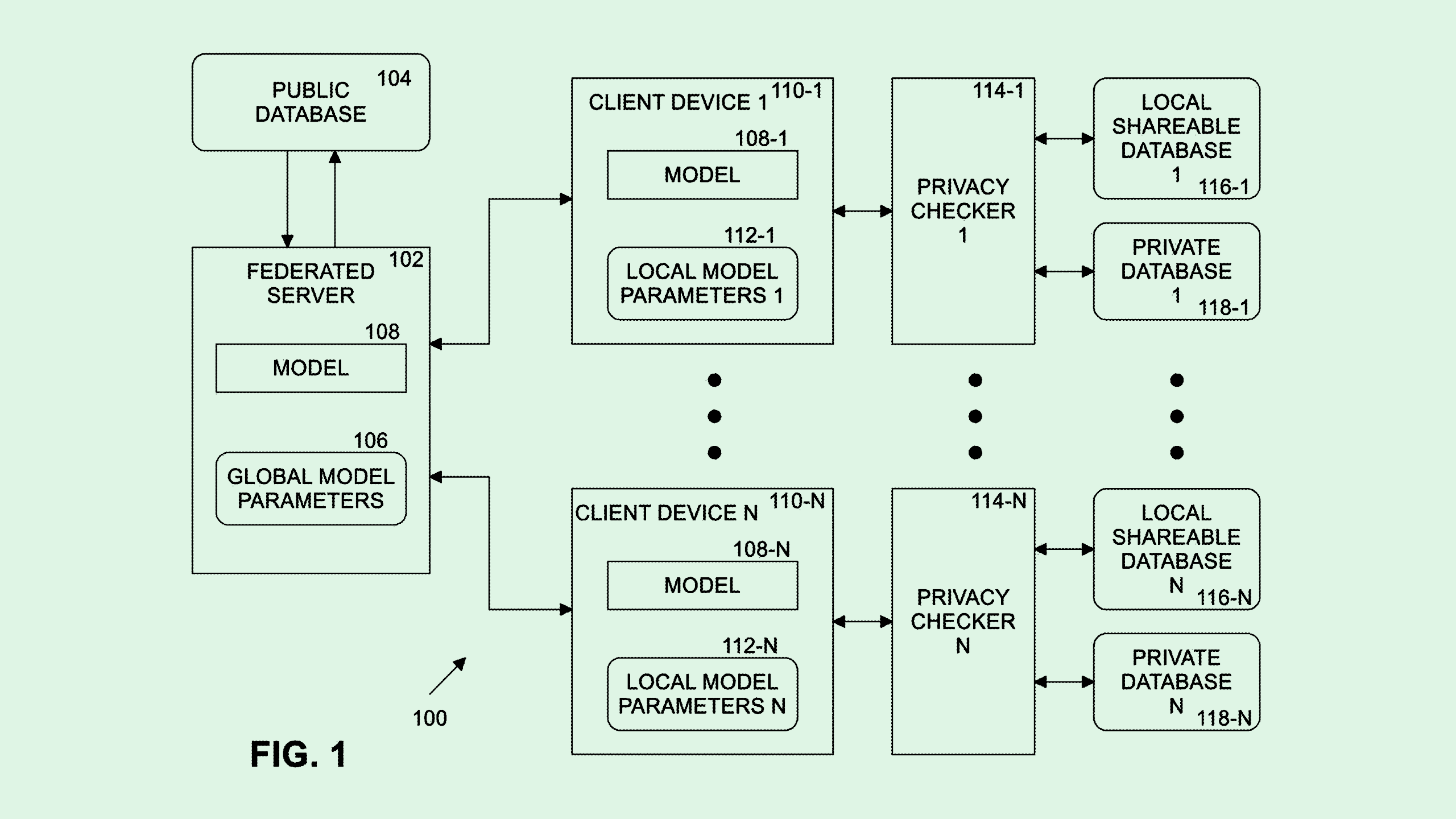
The company filed a patent application for “mitigating private data leakage in a federated learning system.” Federated learning is a type of machine learning in which one central model is trained and shared across devices and servers without sharing the training data itself.
Local data collected via these devices is also used for training. While the original training data from the central server isn’t private or sensitive, the data collected from the distributed devices may be, Intel noted.
“Data utilized for training only at the client device may be inferred or reconstructed back at the centralized federated server, potentially leading to privacy violations and/or data leakage problems,” the company said.
Intel’s system aims to protect any private data collected locally by blurring the lines. When training the model on “local shareable data,” or non-private data that can be shared, the parameters created during that process are “obscured” by adding “noise,” which makes it difficult to pick out sensitive data from the parameters. Those parameters are then sent back to the main server to contribute to the overall model.
Next, the global model is modified in a way that allows it to classify private data, using those obscured parameters. In this process, a “privacy checker” is added “on top of the global model to help identify private data.” Finally, the model is trained on local private data without the risk of that data being leaked or compromised.
Since federated training techniques are useful in Internet-of-Things contexts, this patent takes an extra step to protect data that may be collected on any distributed device, whether it be a smart speaker, a connected vehicle, or industrial robotics.
While the AI industry has set its sights on making large language models even larger, it’s often forgotten that AI already exists all around us, said Pakshi Rajan, VP of product at AI data security company Portal26.
“A lot of AI that we actually see in our daily life is federated learning,” said Rajan. “It’s what we see in Alexa and Siri, stuff that’s actually in our living room, even in driverless cars.”
Those devices are only getting smarter, as evidenced by companies like Meta, Apple, Google, and Microsoft filing a bevy of patents over the last year to make AI assistants and speakers even more capable.
And despite the prevalence of the devices, there are still a lot of unknowns about how these firms treat your data, said Rajan. “We live in a world where we assume these big companies are going to do the responsible thing, but they may or may not,” he said. “So I think a patent like this starts to bring more attention to best practices.”
Privacy-preserving tech like this is vital given that AI training already presents data security risks if not done properly. Intel’s tech intends to put safeguards in place to protect the data collected by the AI that runs our day-to-day lives.
Intel has taken on AI privacy in its patents in the past. Some of its previous applications include a way to preserve privacy in voice assistants and a filing for
“secure model generation and testing.” Intel’s main business is selling “shovels in a gold rush,” said Rajan, referring to its chips. As Internet-of-Things devices get more capable, collect more data and thereby present greater risks that require privacy checkers, Intel, in turn, sells “beefier” chips, said Rajan.
Plus, while the company lags behind Nvidia and AMD in the AI chips race, researching tech that focuses on safety and ethics could help it differentiate itself in a crowded market that’s largely focused on growth at all costs.
Recent News
-
Google Patent Highlights AI and Quantum’s Symbiotic Relationship

Photo via U.S. Patent and Trademark Office

-

Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office



-
Microsoft’s Cybersecurity Strength Could Boost AI Bet
Photo via U.S. Patent and Trademark Office

-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office


-
Nvidia May Take Humans out of the Data Center Equation
Photo via U.S. Patent and Trademark Office
-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office