Adobe’s Multimodal Model Could Make AI Summaries Clearer
The company may be looking to boost its AI capabilities after the fallout of it’s proposed acquisition of competitor Figma.
Sign up to uncover the latest in emerging technology.
Adobe wants to make sure its AI-generated summaries stay focused.
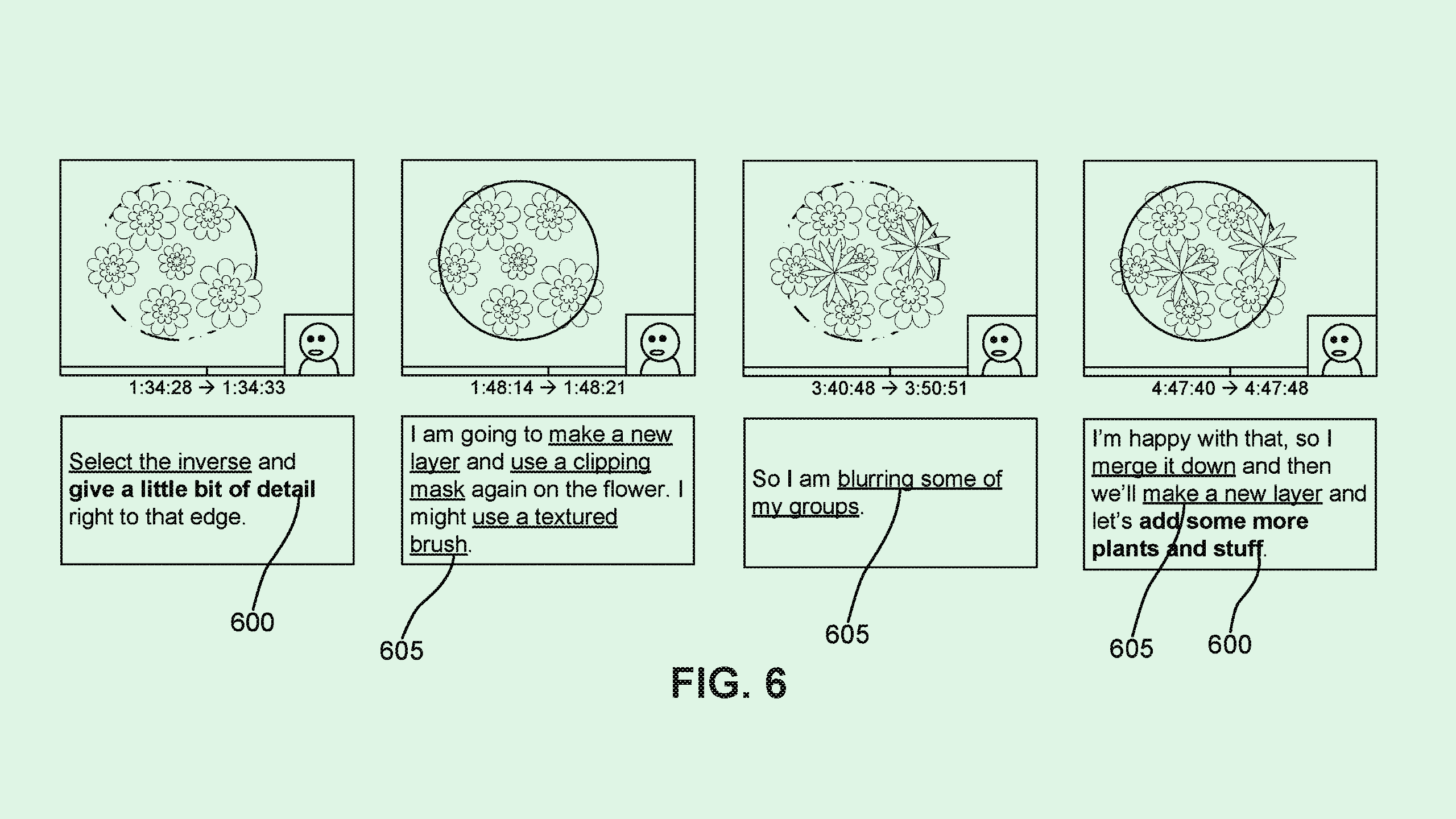
The tech firm wants to patent a “multimodal intent discovery system” for videos. Adobe’s tool aims to give AI summarization more context by taking into account both text transcripts and video data, thereby making its summaries more accurate.
“Some systems predict speaker intents by analyzing the transcript of a sentence in the video and its surrounding context,” Adobe said. “However, in longer videos such as livestream tutorials, off-topic conversations and other noise can result in inaccurate predictions of intent.”
Adobe’s method identifies what’s relevant in a video stream using a text encoder and visual encoder to generate both textual and visual feature data. (An encoder essentially translates the raw data into something that an AI model can use and understand).
Using both streams of data, a machine learning model predicts the intent of what a speaker may be saying in a video. The system also includes several “cross-attention layers” that ensure that the model’s predictions efficiently take into account both visual data and language data.
Finally, those predictions are compared to the model’s ground-truth training data, and the model’s parameters are updated.
In practice, this would allow an AI summarization tool to properly filter out background noise and side conversations in longer videos and live streams, cutting to the chase of what they may actually be about. For example, if a person is doing a DIY demonstration during a livestream, and is interrupted by someone talking to them briefly in the background, Adobe’s system would filter that out of a summary.
Adobe’s patent hits on a common theme that comes up in tech patent filings: AI models often struggle to understand what people truly mean when they say things. Only thinking about the words themselves works best in “well-constrained contexts,” the patent notes, such as an email or search query, but often fails when applied to video and audio.
This concept rings true for emotion detecting AI tech in particular, as it’s hard for an AI model to conceptualize what a person is actually trying to say or how they feel when everyone speaks and emotes differently.
However, as Adobe’s patent explains, the solution to this may be multi-modal.That’s because the more streams of data an AI system has to work with, the better it’ll do its job. AI that takes into account both the words that a person is saying and the context of the scene around them may be able to understand what’s happening with more accuracy.
Adobe has been grinding away at integrating AI throughout its design suite. The company’s patent activity includes things like AI face anonymization, personalized in-app recommendations and visually-guided machine learning models. The company also offers enterprise generative AI tools through Adobe Sensei, and its AI image generator Firefly, which the company claims is safe for commercial use.
While the company’s AI work is more niche than that of Google, Microsoft or OpenAI, it’s continued to add in AI in a way that makes sense for its existing audience. In an interview with Bloomberg this week, Nancy Tengler, CEO and CIO at Laffer Tengler Investments, called Adobe the “unsung hero of AI, because they really do have a lot of use cases for AI in their models.”
Plus, after the fallout of Adobe and Figma’s proposed merger, the company may be looking towards AI to stay competitive as Figma ups its own AI integrations.
Recent News
-
Google Patent Highlights AI and Quantum’s Symbiotic Relationship

Photo via U.S. Patent and Trademark Office

-

Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office


-
Meta To Try Out AI Business Tools as Enterprise Market Heats Up
Photo via U.S. Patent and Trademark Office
-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office

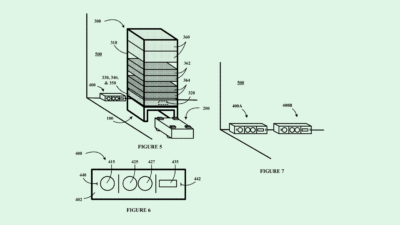
-
Google May Be Giving Glasses Another Go. Will It Succeed?
Photo via U.S. Patent and Trademark Office
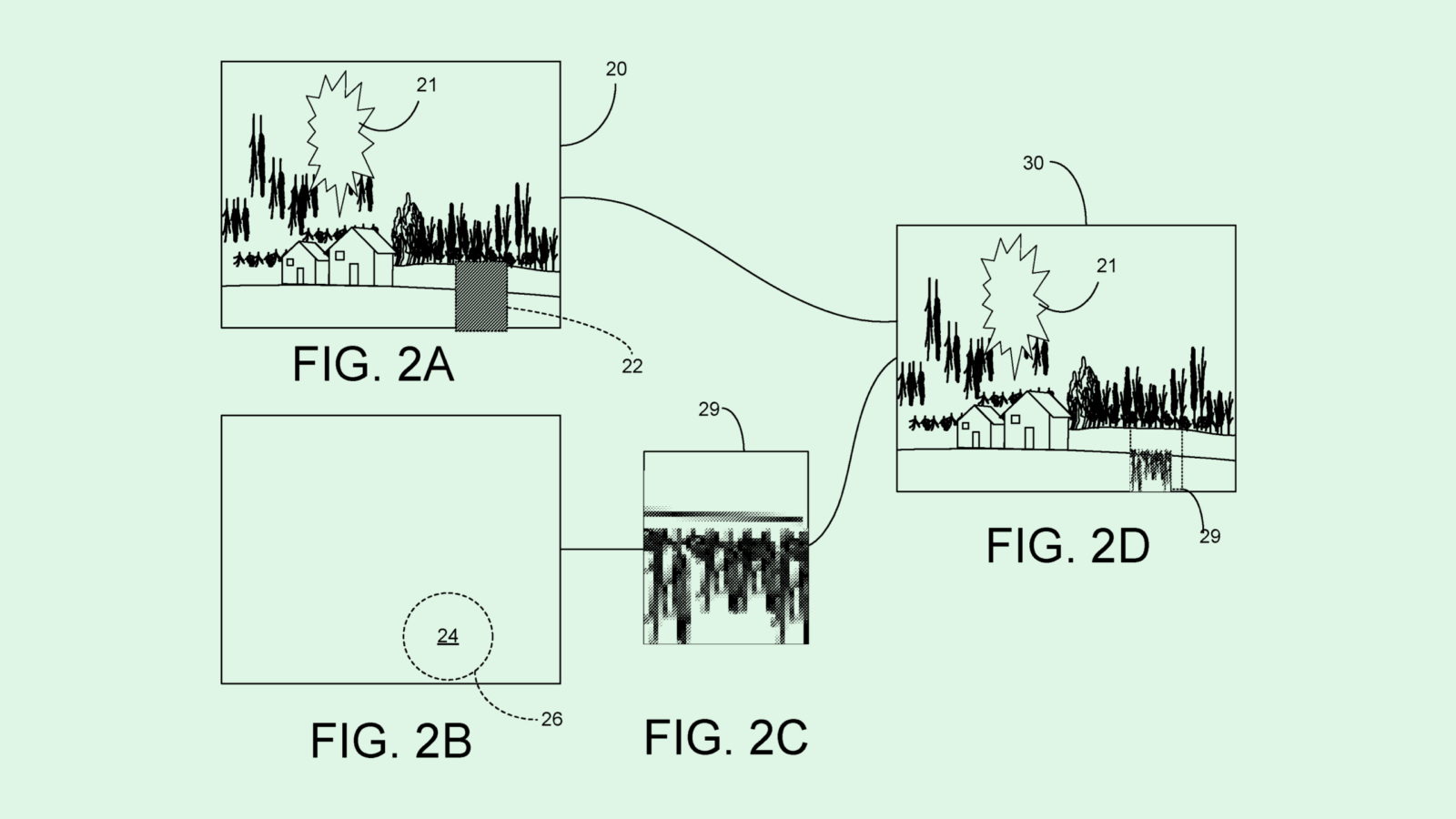
-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office


