DeepMind’s AI Training Tech Shows The Need for Speed
As the AI race gets faster, speed and efficiency in development are becoming vital to keep up.
Sign up to uncover the latest in emerging technology.
DeepMind wants its neural networks to grade each other’s work.
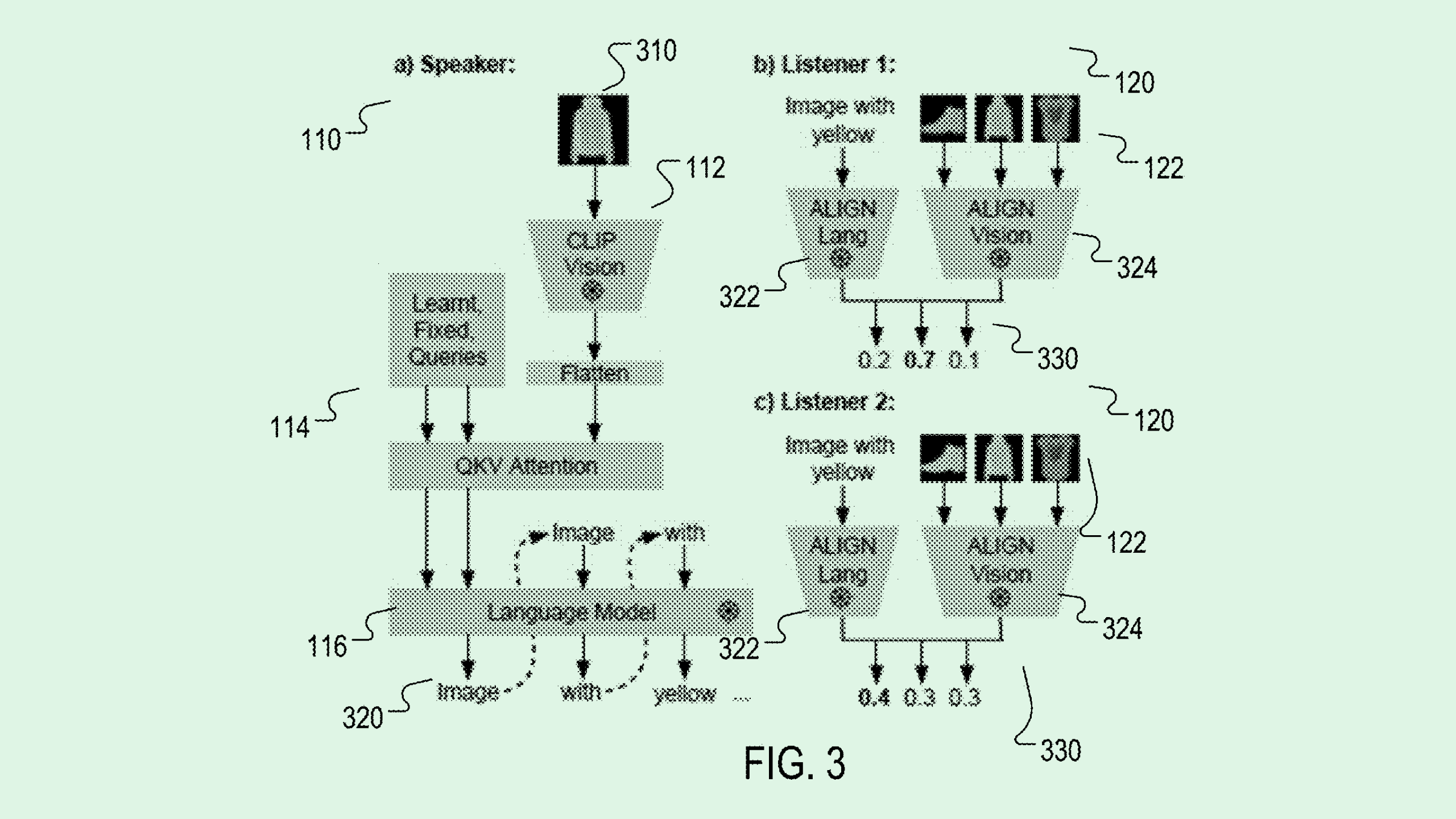
The Google AI division filed a patent for tech that trains a “speaker neural network” using “listener neural networks.” DeepMind’s tech essentially uses reinforcement learning, in which an AI model learns from its mistakes, using one neural network (the speaker) to create text, and at least one other (the listener) to correct that text to be more accurate.
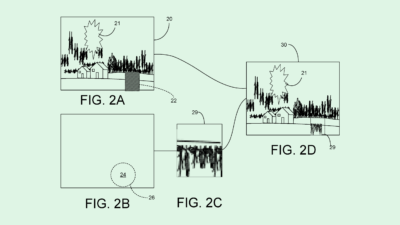
DeepMind’s patent frames this in the context of image captioning. First, the speaker neural network receives a set of training images, processes them and generates a set of captions for the images. Then the listener neural networks would generate “match scores” that determine how well the speaker neural network described the image.
The listener neural networks also adapt those captions to more efficiently describe the images, such as referencing only some characteristics in the image, or avoid referring to a characteristic more than once in one caption.
The more accurate the caption generated by the speaker neural network, the more often the neural network gets a “reward,” which helps “effectively train the speaker to generate captions that have the desired characteristic,” the filing noted.
“By using the described techniques, the system can train the speaker neural network to generate captions that have a desired characteristic without requiring labeled data of captions that have the characteristics,” DeepMind said. This, in turn, saves a lot of time and effort in model training, and could allow for fine-tuning of other image captioning neural networks with less resources.
While this patent specifically targets image captioning, this technique can likely be used outside of that context, creating a way to train an image description system without needing many labeled captions for training data, and subsequently saving resources when training AI.
DeepMind previously sought to patent a system that performs cost benefit analysis of training data versus model performance. Google has also sought to patent tech for fine-tuning of large-scale general models without retraining them completely, and for training a diffusion model with “reduced consumption of computational resources.”
It’s a no-brainer that Google is looking at ways to develop AI quicker and cheaper. The company has integrated AI throughout its Google Workspace offerings and its flagship search engine, and released its own conversational AI tool Bard earlier this year amid the early hype over Chat-GPT.
DeepMind itself, which merged with the Google Brain team in April, has had its own significant breakthroughs. Earlier this month, the division released Gemini, calling it the company’s most capable and general model yet. Gemini, which was launched within Google Bard, was built to be multimodal, meaning it could understand and utilize information across text, code, audio, image and video. And late last week, researchers discovered that Gemini found a solution to a long-standing, unsolved mathematical problem.
According to Wired, Gemini was developed and launched at a far more rapid pace than any previous AI developments from Google. And in a market where new and competing AI tools are popping up every day, speed and efficiency — while maintaining accuracy — are as good as gold.
Recent News
-
Google Patent Highlights AI and Quantum’s Symbiotic Relationship

Photo via U.S. Patent and Trademark Office

-

Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office



-
Microsoft’s Cybersecurity Strength Could Boost AI Bet
Photo via U.S. Patent and Trademark Office

-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office


-
Nvidia May Take Humans out of the Data Center Equation
Photo via U.S. Patent and Trademark Office
-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office