Intel Wants to Beat Bias in AI Training Data
Plus, how experts think AI can be adopted ethically.

Sign up to uncover the latest in emerging technology.
Intel wants to make sure its AI is fair to everyone.
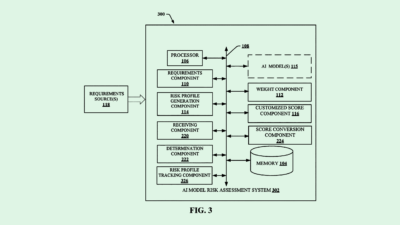
The chipmaker filed a patent application for a system that recognizes “social biases” in AI models by calculating the likelihood that a visual data set contains images reflecting said biases. Because biased AI can emerge from biased training data, Intel said that a model needs to be able to “simulate both human visual perception and implicit judgments.”
“Bias is in the eye of the beholder, literally,” Intel said in its filing. “Social biases are transmitted through artificial intelligence (AI) applications starting from the datasets on which they are trained. Datasets should accurately represent diversity, equity and inclusion.”
Intel’s tech figures out what first draws someone’s attention when looking at an image. (This can be an image from training data or an image that was output by an already-trained model). This system relies on what Intel calls a “saliency model,” or one that can understand and replicate where a human would look to determine the most biased aspect of a given image or scene.
The system then turns out a social bias score of low, medium or high for each image or video analyzed. If a certain amount of bias is detected from the output of an AI model, Intel’s system has two options: It will automatically retrain it using low-bias score visual data, or it will modify the model’s parameters to reduce bias.
The company claims this model uses “psychophysiological models of human perception,” rather than just behavioral data related to human-computer interactions, to make its determinations. The model itself is trained on large sets of unbiased visual data and “bias gaze heat maps” collected from actual people.
But one thing to consider: Many AI training data bias detection tools already exist in the market, many of which are available for free on GitHub. So, whether or not this is actually patentable is up in the air.

The Competitive Landscape
Intel has filed patent applications for dozens of AI-related inventions in recent months spanning several of its business units, seeking to get a grip on everything from AI game graphics rendering to energy-efficient model training to keeping AI data safe after a model has been created.
But compared to others in the sector, Intel has struggled to keep up in the AI arms race. The company’s market share represents a small fraction of AI industry darling NVIDIA: According to Reuters, Intel holds 80% of the AI chip industry market share, leaving AMD in second place at around 20% and Intel at less than 1%. NVIDIA’s customers include big tech firms like Meta, Google and AWS. And NVIDIA doubling its sales on demand for its AI chips in the recent quarter dwarfs Intel and other competitors even more.
On the software side, NVIDIA also dominates with its CUDA development toolkit, which gives developers access to a library of AI acceleration tools, said Romeo Alvarez, director and research analyst at William O’Neil. Plus, the AI development software market itself is only getting more crowded, as tech giants like Google, Microsoft and Amazon are all grinding away at a broad range of AI software innovations.

So how did NVIDIA gain its lead? According to Alvarez, the company read the tea leaves early that GPUs for AI development and computing generally were the tech of the future, and started investing earlier than its competitors. The company built an ecosystem, he said, offering developers everything they need to do their jobs well. Now that the future is here, Intel and others are simply trying to play catch-up.
And Intel regaining market share won’t be an easy task, Alvarez said. For one, the company would need to create an ecosystem of both hardware and software tools that rivals NVIDIA’s in quality and price. Then comes the harder part: convincing developers to ditch NVIDIA’s ecosystem for its own. Overall, it could take years to gain its footing, he said.
“(Intel) doesn’t have a clear ecosystem,” said Alvarez. “They’re coming out with new chips, but in terms of the software side of things, they’re still very far off. And I think it’s going to be tough for anyone to incentivize developers to move away from one ecosystem to another.”
But all hope isn’t lost: The company’s shares rallied last week on CEO Pat Gelsinger’s announcement at the Deutsche Bank technology conference that it’s likely to hit its third-quarter projections. He optimistically noted that, despite NVIDIA’s lead, it won’t take long for Intel to start racking up orders for AI chips. “They’re doing well. We all have to give them credit,” Gelsinger said. “But we’re going to show up.”
Plus, with Intel’s recent debut of its Sierra Forest data center chip, which it claims has 240% better performance per watt of electricity than its predecessor, the company’s product roadmap is becoming more clear, said Alvarez. “They’re making the right moves,” he said. “But what it’s going to take for companies like Meta, AWS and Google to move away from NVIDIA and try something new, that’s a big question mark.
From the experts
Patent Drop asked AI experts how they thought the tech could be trained and adopted responsibly.
Patent Drop: Intel’s patent suggests the company is working on a tool to find biases in AI training data. Why is good-quality, unbiased training data so vital?
Brian P. Green, author and director of technology ethics at the Markkula Center for Applied Ethics at Santa Clara University: It’s garbage in, garbage out. If you have biased data going into training your model, you’re going to end up with a model that is biased, and is reproducing those biases in its predictions or in its recommendations. So if you’re using it to, say, predict who you should give a loan to, then that ends up just reproducing the bias in an automated form. It takes all that human bias that was there in individual people, and just scales it up. It’s really important to make sure that these systems are not just reproducing human biases at a mass scale.
Vinod Iyengar, head of product at AI training engine ThirdAI: Most of these (public) models that you see all use deep learning, which is a family of techniques to train models using unstructured data. With this new way of AI, what you’re seeing is people using raw, unstructured data but not doing a lot of cleaning … The problem with that is you take in a lot of garbage. And generally, there’s a lot more information on the web based on western countries, so your model is already disproportionate to the population that exists in the world.
Liran Hason, CEO and co-founder at machine learning monitoring company Aporia: Unlike traditional software, where you have an engineer writing code so that you can have 100% clearance on what’s going to happen in each and every scenario, AI is more similar to the way we learn as people. So when training data is biased towards or against specific populations, the resulting model will inherit this bias, behavior and characteristics, meaning that the resulting decisions it makes are going to be discriminative.
PD: Can biases develop after an AI model is trained and put to use? If so, how can we spot them and what can be done about it?
Iyengar: Biases don’t develop post facto unless you use some kind of feedback mechanism, where you’re basically providing feedback that is often used to update the model. You need to have enough protections in place when you’re collecting feedback because these systems can be gamed for nefarious purposes, or even (non-maliciously) just by the nature of who’s using the product. By default, a model just produces results. But if you use those results to change your model, you need to be very careful.
PD: What should tech leaders, startups and big tech firms that are rushing towards broader AI adoption take into consideration?
Hason: There are two levers to this: One side is we want to have AI as soon as possible. But the other side is the risks that come with this extremely powerful technology. So as for what stakeholders need to do, I think that for the very least, they should allocate resources, like a team of people, dedicated to constantly tracking, monitoring, and ensuring that these systems work properly in a responsible manner.
PD: With regard to biases, how can AI be adopted ethically? What needs to be done?
Green: I think the number one thing is to recognize that it’s not just going to be ethical on its own, you need to put work into it. You need to be paying attention. You need to be getting feedback from users, and you need to be doing due diligence ultimately to make sure the system is operating the way that it should be.
The second step is to ask yourself: Is this model actually helping people? You might have a perfectly unbiased algorithm on some social media network that’s just spreading misinformation everywhere, and have to put bias into the system to prevent that. Just because something’s unbiased doesn’t mean it’s necessarily doing good.
Recent News
-
Amazon Tries to Help Alexa Get Personal

Photo via U.S. Patent and Trademark Office
-

Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office


-
Adobe Wants to Fix When AI Starts to Drift
Photo via U.S. Patent and Trademark Office
-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office
-
Microsoft Patent Could Make AI Integration More Personalized
Photo via U.S. Patent and Trademark Office
-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office