Nvidia Patent Details Adaptable Conversational AI Models
However, these kinds of modifications come at the expense of high-level customization and accuracy.
Sign up to uncover the latest in emerging technology.
Nvidia may want to make polymath AI models.
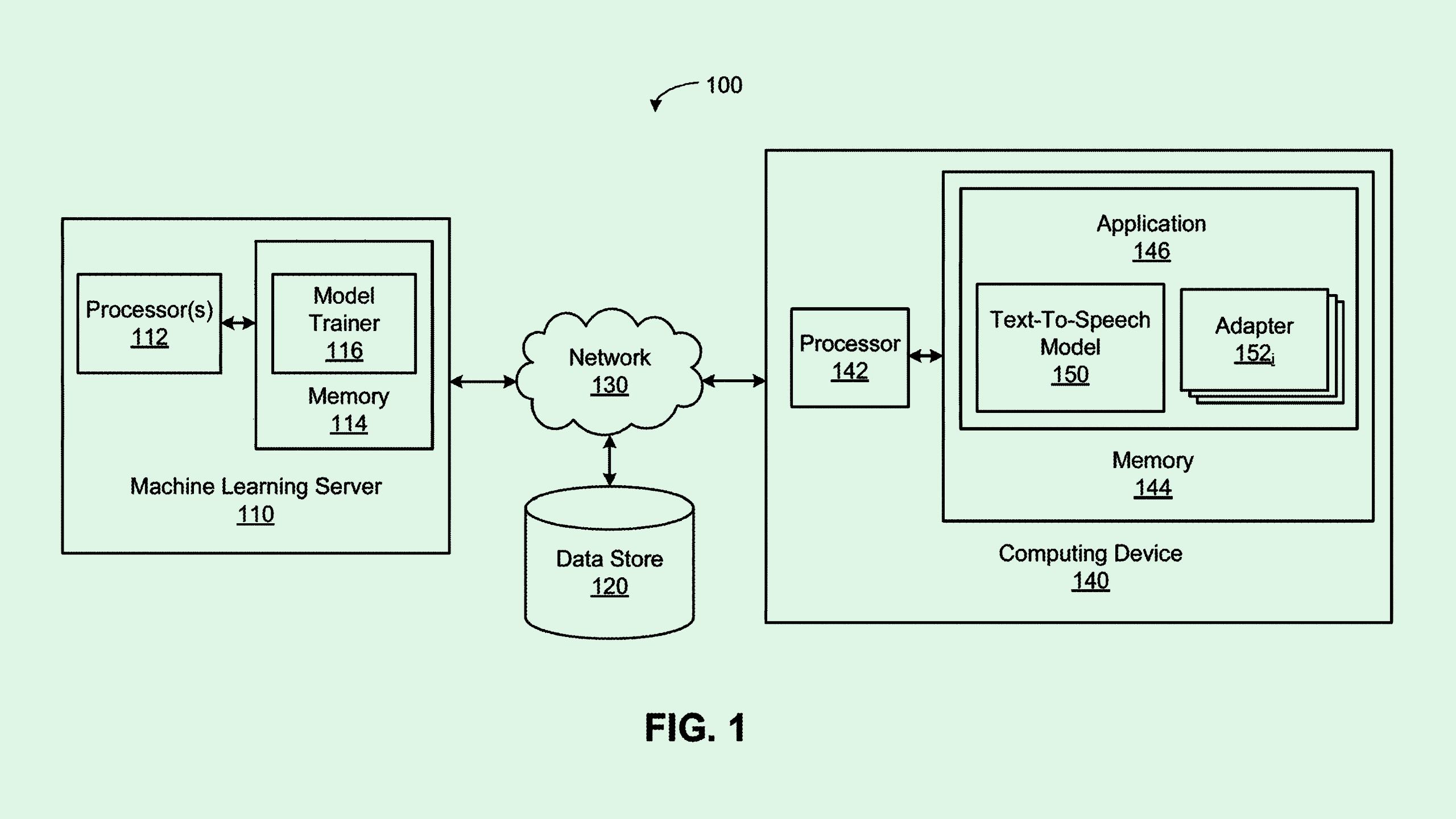
The company seeks to patent a system for “customizing text-to-speech language models” using “adapters” for conversational AI systems. Nvidia’s tech essential aims to create speech models that can understand and adapt to several different users speaking to it.
Training speech models generally takes a large amount of data, and customizing those models requires a large amount of data and training resources for each new user. Additionally, when a model takes in too much information related to several different users, the quality of its output can go down, the filing notes.
Nvidia’s tech aims to avoid resource drain and “overtraining” of these models by training parts of the model, rather than the entire thing, to the specifications of each speaker. Nvidia’s system first gives a model a base training by using a broad dataset filled with reams of speech data.
The next step is adding “adapter layers,” which are meant to be modified to accommodate the information of a specific user. During this part of training, the parameters of the base model are “frozen,” meaning they’re fixed and cannot be changed. New adapter layers can be added whenever new speakers (or groups of speakers) are introduced
The result is a speech model that can essentially know which user is talking to it, as well as any context or information around said user. For example, in a household with several different occupants, a smart speaker trained in this way would be able to differentiate between each one.
The concepts are quite similar to those being put into use in large language models, said Vinod Iyengar, VP of product and go-to-market at ThirdAI. If a company wants to use a language model for its own purposes, rather than building one itself from scratch, it’s common to use adapters like these to modify outputs.
These layers can be thrown on top of existing architecture without having to do anything to the language model itself. And because massive models take tons of time, resources, and money to create, this can save a smaller company from having to break the bank if they want to integrate AI.
But training in this way comes with sacrifices, Iyengar noted. While you can modify your outputs to a certain extent, it’s still less adaptable than creating your own niche model. Using a generalized model with an extra layer may also prove less accurate to your specific needs. Iyengar likened it to putting lipstick on a pig: “The core problem is not solved” when it comes to how resource-intensive foundational AI training is, so people are looking for workarounds.
“The reality is customization is very hard,” said Iyengar. “You see a lot of tricks to solve the last mile, but you give up some accuracy and some amount of control to maybe get a good enough solution for a lot of these use cases.”
Additionally, adapters like these may get you stuck within a certain development ecosystem – which, for Nvidia, is certainly a boon. While the company makes most of its revenue from chips, its CUDA software ecosystem has everything a developer could want. The goal with this is to make it “sticky,” said Iyengar, offering so much value that its customers become hooked.
Recent News
-
Google Patent Highlights AI and Quantum’s Symbiotic Relationship

Photo via U.S. Patent and Trademark Office

-

Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office



-
Microsoft’s Cybersecurity Strength Could Boost AI Bet
Photo via U.S. Patent and Trademark Office

-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office


-
Snap Boosts Digital Ad Platform to Compete with Meta, TikTok
Photo via U.S. Patent and Trademark Office
-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office