Nvidia’s Two-Model System Could Make AI Less of a Power Drain
The company is seeking to patent a system which uses a general purpose AI model to create training data for a task-specific one.

Sign up to uncover the latest in emerging technology.
Nvidia wants its AI models to be able to train one another.
The chip giant filed a patent application for “task-specific machine learning operations” that use training data created by general purpose models to enable “automated model development.” This system uses the input given and output generated by an AI model that’s already been trained to subsequently train another AI model for a specific task.
First, a trained machine learning model is fed a number of inputs, such as questions or requests, to prompt it to give answers. The system then stores those call-and-response pairs, and uses those as training data for a different model. Once trained, the responses of the second model are tested against that of the first to check if they’re in agreement, and if they surpass a certain threshold, the second model is deployed.
Nvidia’s method allows a general purpose model to help train a task-specific one by only training the new model on call-and-response pairs that are relevant to the task at hand. “In this manner, lighter, less computational intensive models may be rapidly developed and deployed by leveraging benefits of more sophisticated, more computationally intensive models,” Nvidia said.
This method could help bypass the tedious process of obtaining and annotating large datasets, Nvidia noted. It also avoids using general purpose models for specific tasks, which “may lead to poor results, which may be exacerbated when expected user queries are specific to a particular domain that the models may not be sufficiently train(ed) on.”

The inspiration for this technique comes from a similar method of using two-tiered models that has cropped up recently among large language model developers, said Vinod Iyengar, head of product at ThirdAI. Nvidia’s patent, however, abstracts the concept to apply it to other use cases and allows for more automation within AI training and deployment.
“This gets close to automated model development because between those two models, they can teach themselves, and learn to be better and better at particular problems,” he said.
Nvidia also says that a major benefit of this system is creating models that offer the same benefits as general purpose ones without sucking up as much power. While this doesn’t lower the cost of actually running a large-scale general purpose model, Iyengar noted, it creates a “hybrid system” that gives the benefits of those models at a significantly lower cost.
This approach makes sense for Nvidia to keep its lead in the AI race. The company already dominates with its GPUs and CUDA development kit, and reported $10.3 billion in data center revenue (which includes its AI work) in the recent quarter, up 171% year on year. A patent like this adds another tool to its ecosystem, which has become wildly popular among AI developers. Plus, it creates a solution for those who don’t want to invest the cost and energy into creating general purpose models, drawing in a wider audience.
However, at the end of the day, it’s still a Band-aid for the much larger issue of the cost and energy problem that large models present.
“Yes, something like this is interesting, but we should always be thinking about how to make the whole computing system cheaper,” said Iyengar. “And how to make things less dependent on one single company. We still need to think broadly about how to reduce overall cost.”
Recent News
-
Google Patent Highlights AI and Quantum’s Symbiotic Relationship

Photo via U.S. Patent and Trademark Office

-

Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office


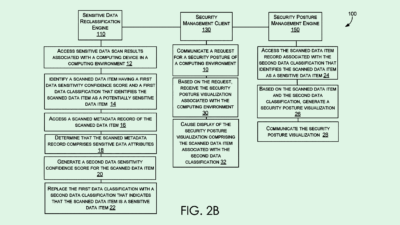
-
Meta To Try Out AI Business Tools as Enterprise Market Heats Up
Photo via U.S. Patent and Trademark Office
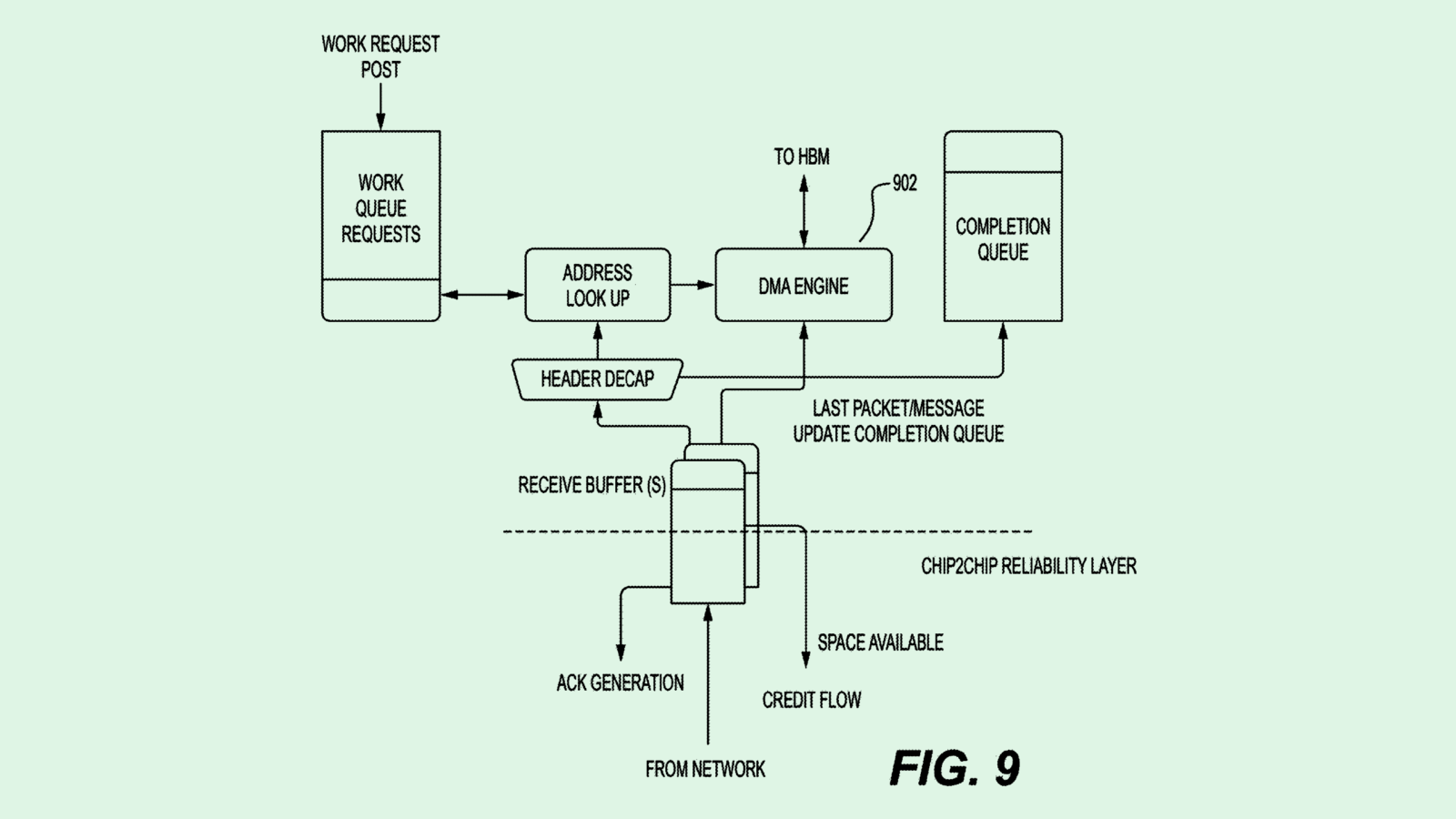
-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office

-
Google May Be Giving Glasses Another Go. Will It Succeed?
Photo via U.S. Patent and Trademark Office
-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office


