Nvidia May Want AI to Create Its Own Data
While the proposed tech could save a lot of resources in AI training, it faces major problems if it can reproduce biases and inaccuracies.
Sign up to uncover the latest in emerging technology.
AI eats up a lot of data. Nvidia wants its models to start making their own lunch.
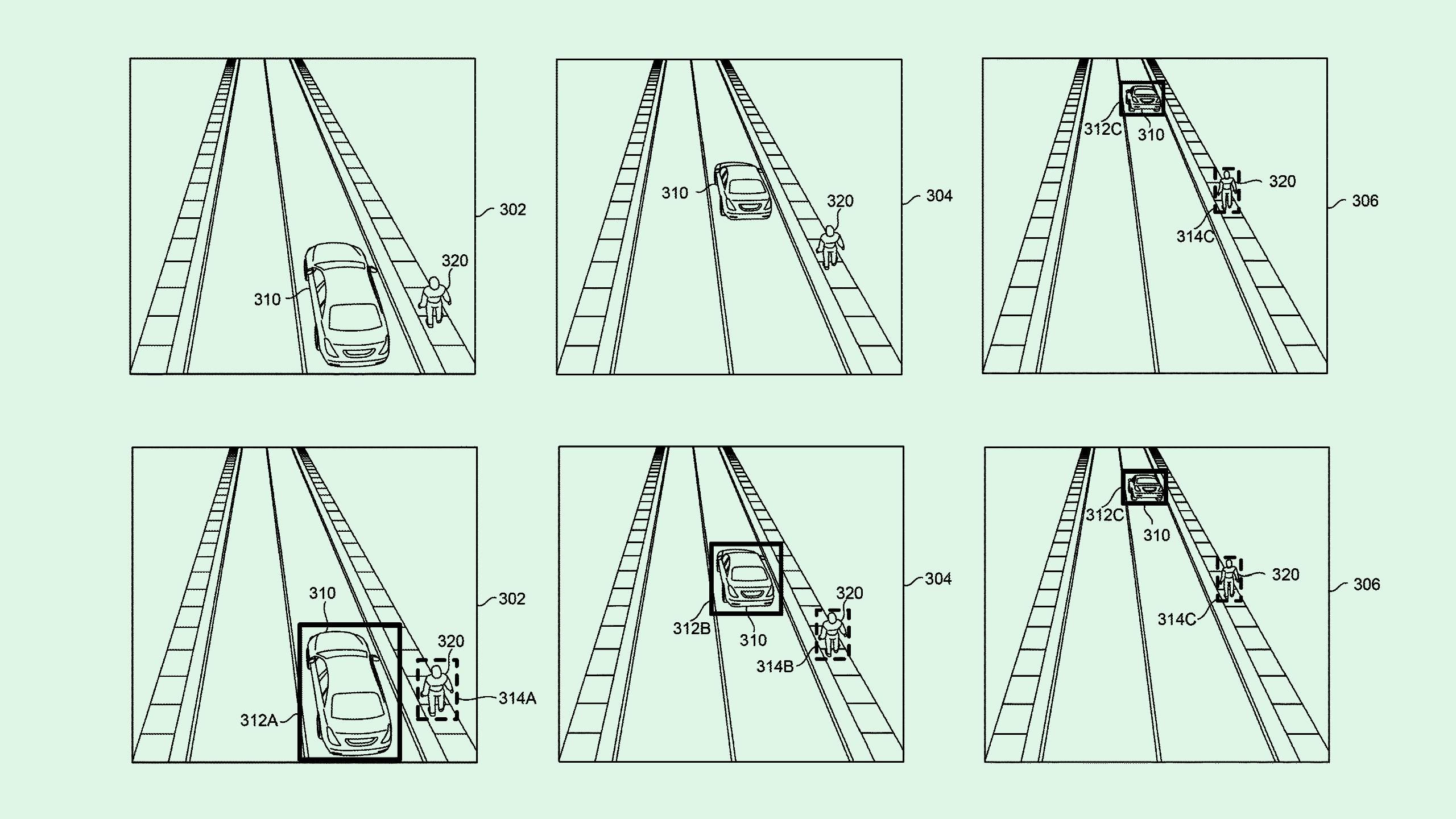
The company is seeking to patent “automatic generation of ground truth data” for training and retraining machine learning models, specifically those used in object detection. Ground truth data is the information that a developer wants its model to understand as reality.
“This process of ground truth generation and retraining requires significant effort, time, and resources,” Nvidia said in its filing. “In addition, because the accuracy of these conventional systems is limited to the perspectives used to train the machine learning models, these systems are not easily scalable.”
Nvidia’s filing outlines a system which automatically creates new ground truth data for a computer vision system for images that are captured at different perspectives. When a camera captures an image of an object from one angle, this system first uses a machine learning model to generate a prediction of how an object may look from multiple angles.
Then, an “object tracking algorithm” can then take those predictions to decipher where the object wasn’t detected by the machine learning model, aiming to basically widen its view. From this, the AI model can essentially retrain itself by automatically creating ground truth labels based on this data.
Nvidia noted that, along with updating existing computer vision models, this data could be used to train other models and “increase the robustness of a ground truth data set” for training.
Nvidia’s patent aims to solve a major problem with computer vision: the expensive nature of high-quality visual training data, said Vinod Iyengar, head of product and go-to-market for AI training engine ThirdAI. Because this data typically needs to be labeled by actual humans, the cost for creating a large, high-quality training data set can be extremely high and very time-consuming.
But Nvidia’s method aims to take the human out of the loop by having the AI model essentially eat its own outputs. The problem? Biases and inaccuracies, said Iyengar.
Because the model would essentially be in charge of retraining itself, if the initial model contains any biases or inaccuracies, those would only replicate and grow stronger every time Nvidia’s system did its thing. That could present issues when considering that this kind of computer vision could be used in self-driving cars and surveillance.
“The dependence on the initial model’s accuracy is a concern,” said Iyengar. “What they will probably need is to put a lot of checks and balances, or even human oversight, in the generation process so that if there are any biases, those won’t be recaptured.”
That said, if Nvidia was able to account for this issue, it could help the company gain market share in the fragmented autonomous vehicles space, said Iyengar. Nvidia currently dominates a large part of the AI market with its GPUs used for AI training and its ecosystem of developer tools. But it has some major competition in the self-driving car market with companies such as GM-owned Cruise, Google-owned Waymo and Amazon-owned Zoox.
Plus, this kind of computer vision tech has a ton of use cases. Any developer starting a new visual AI model from scratch that doesn’t want to plow tons of money into training data could find this system useful, Iyengar said, thereby drawing them into using Nvidia’s development ecosystem and GPUs.
“This approach can help someone that’s starting up fresh,” Iyengar said. “You may still need to improve the model with human-labeled data, but it gets you much further along before you even put any money into it.”
Recent News
-
Google Patent Highlights AI and Quantum’s Symbiotic Relationship

Photo via U.S. Patent and Trademark Office

-

Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office


-
Meta To Try Out AI Business Tools as Enterprise Market Heats Up
Photo via U.S. Patent and Trademark Office
-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office

-
Google May Be Giving Glasses Another Go. Will It Succeed?
Photo via U.S. Patent and Trademark Office
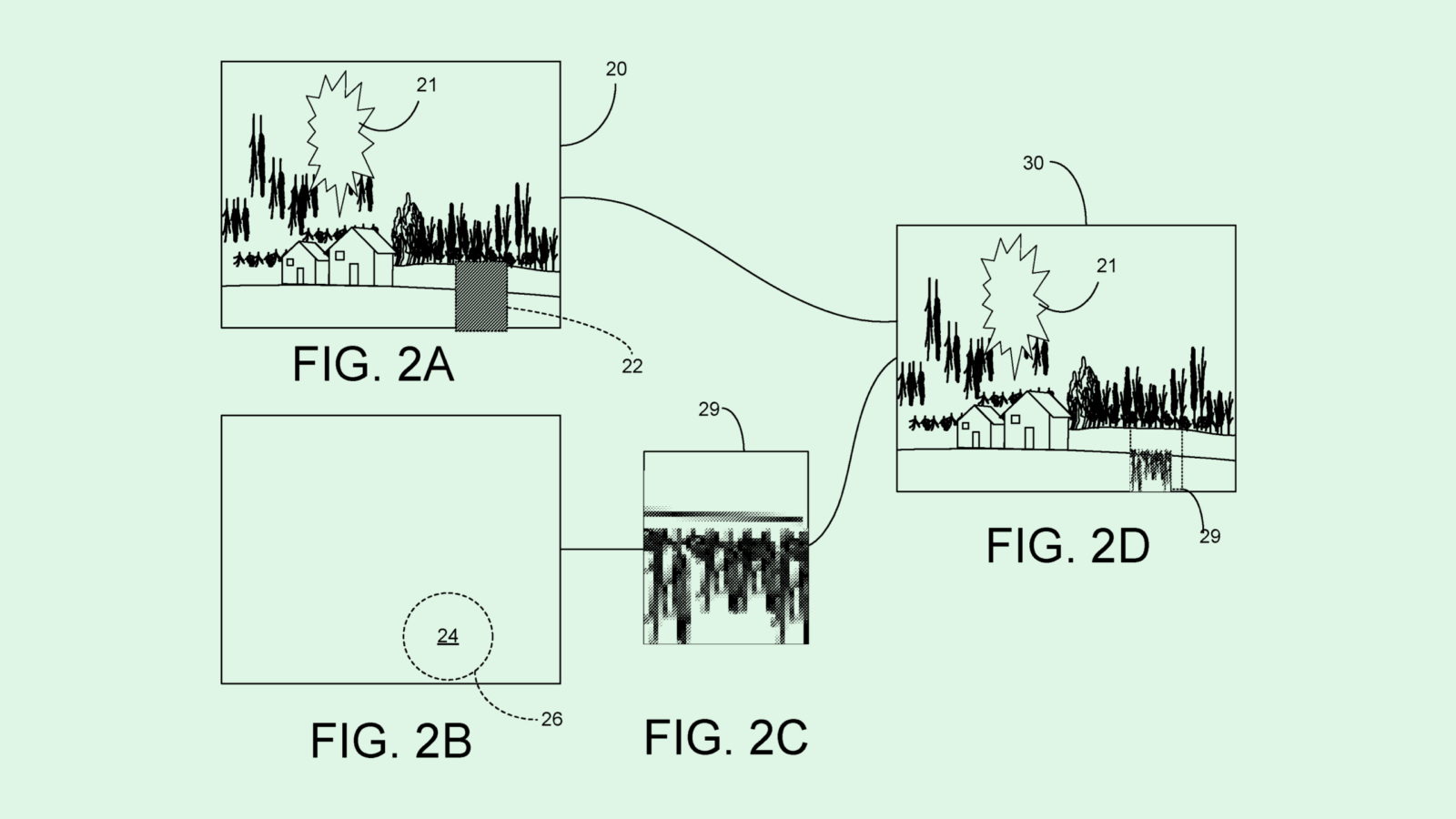
-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office


