Google Wants to Use Machine Learning to Keep AI Data Unbiased
The company’s latest filing adds another solution to several aiming to tackle the ever-present issue of bias at the source.
Sign up to uncover the latest in emerging technology.
Google wants to turn bias away at the door.
The company is seeking to patent a system for “rejecting biased data using a machine learning model.” This tech essentially aims to keep bad datasets from entering a model from the jump, thereby preventing a model from developing biases in the first place.
As AI enables the capability to rapidly collect and analyze data, “data processing techniques must equally overcome issues with bias,” Google said in the filing. “Otherwise, data processing, especially for bulk data, may amplify bias issues and produce results also unparalleled to biases produced by human activity.”
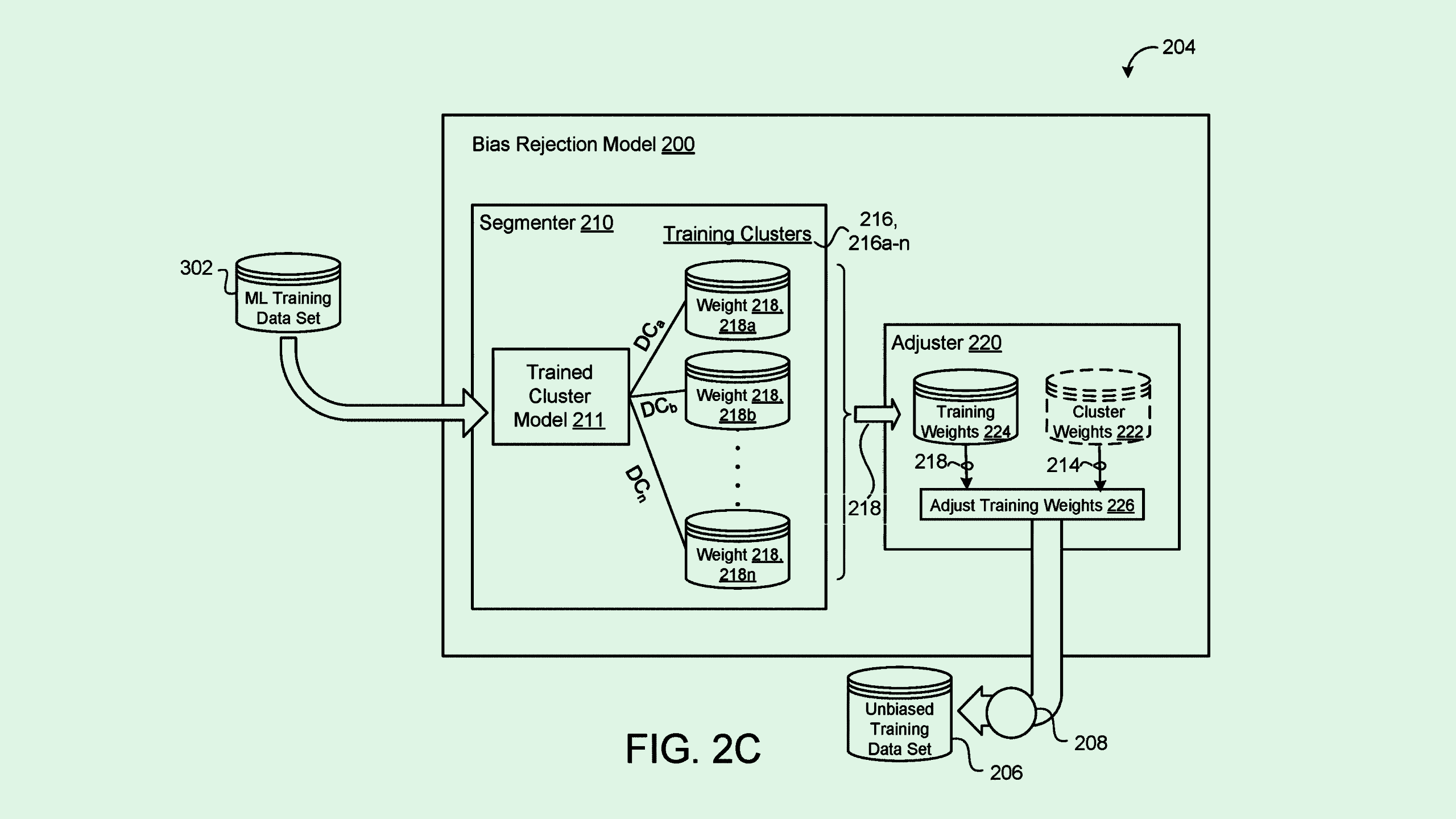
First, Google’s system receives a training dataset that is unbiased and representative of a broader population, which is used to train a “clustering model” that groups similar data points together. This trains the clustering model to put data into categories and properly adjust the weights of data points within the data sets. For reference, the weight of each data point in a data set determines how much influence it has on the machine learning model’s outputs.
Finally, Google’s clustering model is fed other training datasets, which adjust the weights of data points that may be over- or under-represented. While this sounds a bit technical, the outcome of Google’s tech is a way to take bias out of a set of AI training data.
For example, if you have an image data set to train a facial recognition model where more men are represented than women, it may adjust the weights of each category to properly reflect both, making the model less biased and more accurate.
Google’s patent adds to several companies aiming to tackle the ever-present issue of bias in training AI models. AI-inclined tech firms including Adobe, Sony, Microsoft, IBM, and Intel have all sought to patent their own methods of detecting and debiasing for things like image-editing, facial recognition, lending, and more.
An AI model is only as good as the data that it’s trained on. A model taking in a dataset that’s not representative of the task it’s trying to solve will impact its output, with biases growing worse over time. Google’s patent attempts to cut off bias at the source by reconfiguring training data sets, said Brian Green, director of technology ethics at the Markkula Center for Applied Ethics at Santa Clara University.
However, this patent calls into question just how effective debiasing tools may be on large, general-purpose models, Green noted. Massive generative language models and image generators have to take in a ton of data to handle all manner of queries. However, one model can only go so far, he said. “Every model is going to be limited by its dataset, and every dataset is going to be limited by its sampling,” said Green.
Creating unbiased datasets can also create overcorrections that lead to inaccuracies, Green noted. One example of this is when Google’s generative AI tools came under fire in February after its Gemini image generator created historically inaccurate images of racially diverse founding fathers and Nazi-era German soldiers.
The company noted at the time that its models can create images of a wide range of people, which is “generally a good thing because people around the world use it. But it’s missing the mark here.”
As Google works to get AI in front of more consumers with things like its Pixel smartphone, YouTube AI integrations, and its Gemini chatbot, figuring out bias in widely available AI models is imperative. But the solution likely won’t be simple, said Green. “Ultimately, it’s a really complex problem, and it’s going to require a really complex solution.”
Recent News
-
Google Patent Highlights AI and Quantum’s Symbiotic Relationship

Photo via U.S. Patent and Trademark Office

-

Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office



-
Microsoft’s Cybersecurity Strength Could Boost AI Bet
Photo via U.S. Patent and Trademark Office

-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office


-
Google May Be Giving Glasses Another Go. Will It Succeed?
Photo via U.S. Patent and Trademark Office
-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office