Nvidia’s Fair AI Patent Could Improve Facial Recognition Accuracy
While this is a recognized problem in face-reading AI models, Nvidia’s tech relies on synthetic data to achieve balance, which comes with caveats.
Sign up to uncover the latest in emerging technology.
Nvidia wants to strike a balance between accuracy and fairness in its AI models.
The company is seeking to patent a system for “fairness-based” neural network training using both real and synthetic data. This aims to make computer vision models more accurate and fair by creating more balanced datasets.
Fairness in visual recognition models is a “recognized problem,” Nvidia said. While adding synthetic image data into these sets can help create a more balanced ratio of attributes, the “drawbacks are that the synthesized data typically has quality issues and may be biased.”
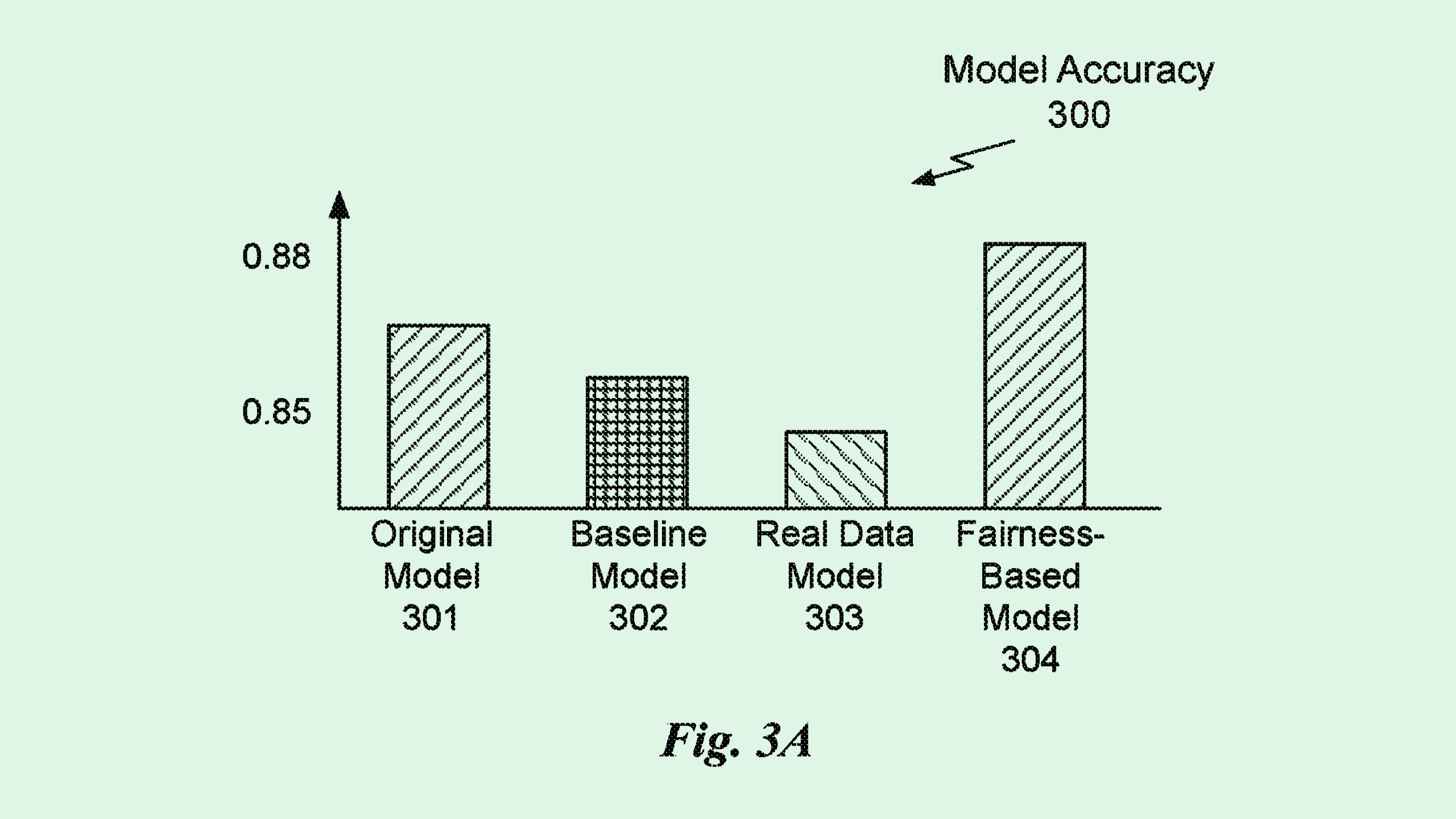
Nvidia’s system aims to fix this by finding the right ratio of synthetic and authentic data to train visual models to more accurately represent different attributes, particularly for gender, age, and skin color. The system first determines the real-versus-synthetic data ratio of the starting dataset, as well as the ratios of data from different attributes.
Nvidia then uses “bilevel optimization,” or a math technique that solves two optimization problems that intersect. This technique balances accuracy and fairness in how much synthetic versus real data is used to represent different attributes.
The system may also employ “group fairness measures” to avoid discriminating against “sensitive groups.” These fairness measures include equalized odds, ensuring an equal amount of false positives and false negatives across groups, and demographic parity, which ensures an equal amount of positive outcomes across groups.
“Compared with conventional solutions, using real and synthetic training data improves accuracy while dynamically adjusting the sampling ratios improves fairness,” Nvidia said.
Nvidia’s patent uses different words to solve a problem that many tech firms are trying to figure out: bias. Patent activity shows that the tech industry wants to take on AI’s bias issue in everything from lending to image models to training data itself.
Nvidia dubbing its tech as a solution for “fairness” is a smart play to set itself apart in the eyes of patent reviewers – even if it is addressing the same issue as the other players, said Bob Rogers, PhD, co-founder of BeeKeeperAI and CEO of Oii.ai.
Focusing on facial recognition as its primary example is another smart angle. Facial recognition and analysis technology notoriously have issues with bias, with a higher error rate with darker-skinned individuals than lighter-skinned ones. And given that this technology is being used in security and policing contexts, “getting that bias out of there is critical,” said Rogers.
“Protecting their own ability to develop tools, both in hardware and software that support facial recognition probably has a lot of value,” said Rogers.
However, Nvidia relies on using synthetic data, which comes with its own caveats. While synthetic data gives developers access to a lot of data, it won’t have enough variation if it’s based on a small sample pool. For example, if you have a small data set of people wearing glasses, and all of the glasses are round, then the synthetic images will mirror that, and the image recognition model won’t know what to do when faced with square ones.
“Because you’re still generating all those synthetic examples off of the basic examples that you have, you still can miss important attributes because you just simply don’t have enough data,” said Rogers.
Nvidia’s tool is a great first step in fixing the bias problem, however, as it provides a litmus test to help developers figure out where exactly their dataset may be lacking, Rogers noted. “if your model changes a lot when you add synthetic examples from underrepresented sets, then you know that you’re focusing on things that are sort of group-centric.”
Recent News
-
Google Patent Highlights AI and Quantum’s Symbiotic Relationship

Photo via U.S. Patent and Trademark Office

-

Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office



-
Microsoft’s Cybersecurity Strength Could Boost AI Bet
Photo via U.S. Patent and Trademark Office

-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office


-
Snap Boosts Digital Ad Platform to Compete with Meta, TikTok
Photo via U.S. Patent and Trademark Office
-
Photo via U.S. Patent and Trademark Office -
Photo via U.S. Patent and Trademark Office